Neural networksand big dataare revolutionizing business operations, forming the core of the AI revolution. Neural networks, inspired by the human brain, consist of interconnected layers that process data, making them effective for tasks like image recognition and predictive analytics. Big data encompasses large, complex datasets characterized by volume, velocity, variety, and value, which traditional tools struggle to handle.
Combining these technologies enables the development of intelligent systems that learn from vast datasets, enhancing performance in various applications. This integration is crucial in sectors like finance, healthcare, and e-commerce, driving advancements and meeting the growing demand for autonomous, smart systems.
Neural networks are modeled after the way the human brain processes information, and they consist of interconnected layers of artificial neurons. These neurons, or nodes, work together to process inputs and generate outputs, enabling the network to recognize patterns, make decisions, or predict outcomes.
Neuron Layers (Input, Hidden, Output)
A neural network is composed of three primary layers:
Input Layer – The input layer receives raw data, such as images or text, and passes it to the next layer for further processing. Each neuron in the input layer represents one feature or variable of the data.
Hidden Layers – Hidden layers perform the actual computation and feature extraction. There can be one or many hidden layers in a neural network, and each neuron in these layers applies weights to the incoming signals, processes them through an activation function, and transmits the result to the next layer.
Output Layer – The output layer produces the final result of the neural network's processing, such as a prediction or classification. For example, in image recognition, the output layer might predict whether an image contains a cat or a dog.
Activation Functions and Weights
Activation Functions – These functions determine whether a neuron should be activated based on the weighted input it receives. Popular activation functions include Sigmoid, ReLU (Rectified Linear Unit), and Tanh. They introduce non-linearity, enabling the network to model complex patterns and interactions in the data.
Weights – Weights represent the strength of connections between neurons and are adjusted during training to improve the network’s accuracy. Neurons multiply their input by these weights to give more or less importance to different features.
Backpropagation and Learning Algorithms
Backpropagation is the core mechanism that allows neural networks to learn. It involves the following steps:
Forward Propagation – The network processes input data and produces an output.
Calculate Error – The error (or loss) is calculated by comparing the network's output with the actual result in the training data.
Backpropagation – The error is propagated backward through the network, adjusting the weights using optimization techniques such as gradient descent.
Weight Update – The weights are updated to minimize the error, and the process is repeated until the network converges to an optimal solution.
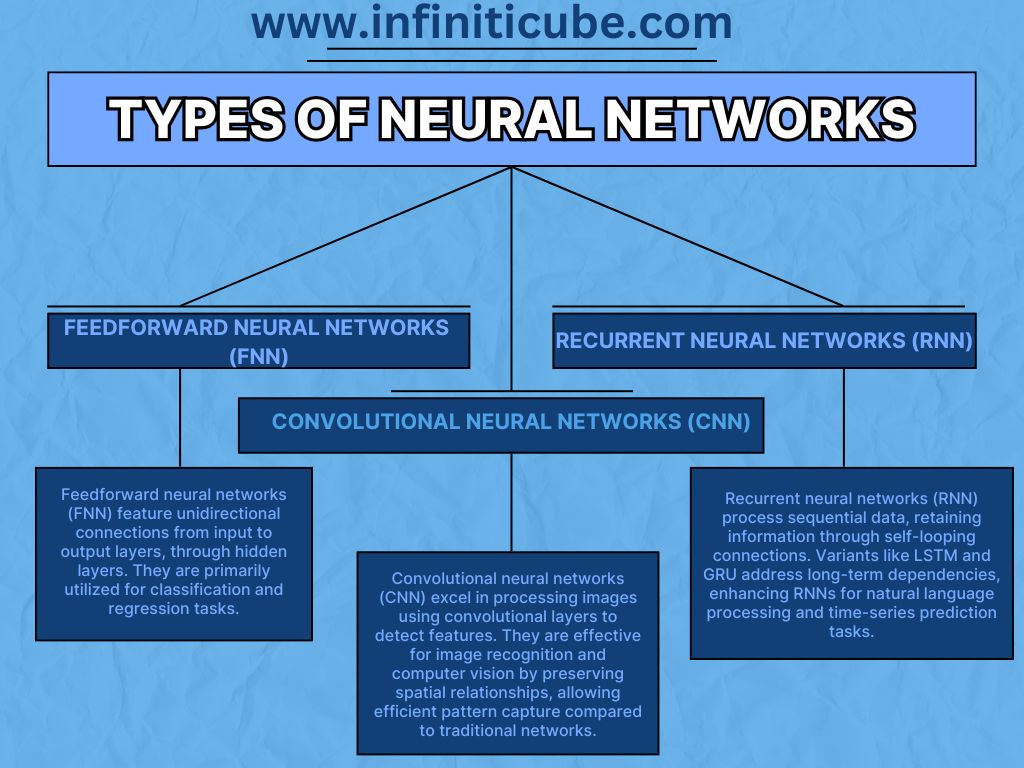
Types of Neural Networks
Neural networks come in various forms, each designed to tackle specific types of tasks and data.
Feedforward Neural Networks (FNN)
The most basic type of neural network, feedforward neural networks (FNN), have connections that flow in one direction from the input layer to the output layer, passing through any hidden layers in between. These networks are typically used for tasks like classification and regression, where the input is mapped to a specific output.
Convolutional Neural Networks (CNN) for Image Processing
Convolutional neural networks (CNN) are specialized for processing grid-like data such as images. They use convolutional layers that apply filters to input data, detecting edges, textures, and other features. CNNs are highly effective in image recognition, object detection, and computer vision applications. By preserving spatial relationships between pixels, CNNs can capture patterns in images and process them more efficiently than traditional feedforward networks.
Recurrent Neural Networks (RNN) for Sequential Data
Recurrent neural networks (RNN) are designed for processing sequential data, such as time-series data, language models, or speech recognition. Unlike FNNs, RNNs have connections that loop back on themselves, allowing them to retain information from previous inputs and recognize patterns over time. Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) help solve issues related to long-term dependencies, making RNNs ideal for tasks like natural language processing and time-series prediction.
How Neural Networks Learn
Neural networks require data to learn and improve their performance over time.
Training with Labeled Datasets
Training a neural network involves feeding it a large amount of labeled data (where each input is paired with the correct output) and letting the network adjust its weights based on the error it makes in predicting the output. This process continues until the network can makeaccurate predictions on unseen data.
Adjusting Weights Based on Error Minimization (Gradient Descent)
During training, the network's goal is to minimize the error between its predicted output and the actual result. This is achieved using an optimization algorithm like gradient descent, which iteratively adjusts the network's weights in a direction that reduces the error. The network gradually improves its ability to make accurate predictions by fine-tuning the weights.
Big data refers to massive, complex datasets that are challenging to process using traditional data processing tools. It provides the fuel needed for machine learning systems, including neural networks, to analyze, learn, and make predictions. These datasets are essential for training AI models because they provide the vast amount of information required to identify patterns and improve decision-making.
Characteristics of Big Data
Big data is often defined by the following characteristics, known as the Four Vs:
Volume – The massive amount of data generated every second from various sources, such as IoT devices, social media platforms, and financial transactions. The larger the dataset, the more information neural networks can use to identify patterns and make accurate predictions.
Velocity – The speed at which data is created and processed. For example, social media platforms generate data in real time, requiring learning systems to process this data efficiently and quickly to stay relevant.
Variety – The different types of data available, including structured data (e.g., databases), semi-structured data (e.g., XML), and unstructured data (e.g., images, videos, text). The diversity of data types is essential for training neural networks across a wide range of tasks.
Veracity – The quality and accuracy of the data. Big data often contains errors, biases, or inconsistencies, making it crucial for organizations to ensure the reliability and integrity of their datasets.
Sources of Big Data
Big data comes from numerous sources across various industries. The following are common sources that feed into machine learning systems:
Internet of Things (IoT) – IoTdevices such as smart sensors, wearable technology, and connected appliances generate vast amounts of real-time data, providing valuable insights for machine learning systems.
Social Media – Platforms like Twitter, Facebook, and Instagram generate enormous amounts of unstructured data (e.g., images, text posts, videos) that can be mined for sentiment analysis, trend detection, and more.
Healthcare Systems – Medical records, diagnostic imaging, andhealth monitoring devices provide critical data for improving patient care and predicting health outcomes through machine learning.
Big Data and Learning Systems
Big data plays a crucial role in developing robust machine learning models, especially neural networks, which thrive on large, diverse datasets to learn and improve their performance.
The Need for Large, Diverse Datasets to Train Neural Networks
Neural networksrely on extensive datasets to recognize patterns and make informed decisions. The more available data, the better the neural network can generalize and make accurate predictions on unseen data. For example, a neural network trained on millions of labeled images can better classify new images than one trained on only a few thousand. Moreover, diversity in data—whether it’s different languages for natural language processing models or various medical conditions for healthcare applications—helps improve the network's ability to handle a wider range of inputs.
Importance of Data Quality and Cleaning
High-quality data is essential for effective training. Data cleaning—the process of removing inaccuracies, duplicates, and irrelevant information—is a critical step before feeding data into a neural network. Poor-quality data can lead to inaccurate predictions, while cleaned and well-structured data allows the network to learn more efficiently. Ensuring data quality also helps mitigate biases that can distort the outcomes of machine learning models.
Impact of Data Variety on Improving Neural Network Accuracy
Diverse datasets are particularly valuable for neural networks because they expose the system to different types of inputs, helping it become more adaptable. For example, a neural network designed to detect objects in images will perform better when trained on varied images (e.g., different angles, lighting conditions, or object sizes). Similarly, in natural language processing, training on data from multiple languages or dialects improves the model's language understanding capabilities. Variety in data strengthens the neural network’s ability to generalize across different scenarios, leading to greater accuracy and reliability.
Neural networks are designed to learn by recognizing patterns in data, and their performance improves dramatically with larger, more diverse datasets. The more data neural networks process, the better they become at making accurate predictions and identifying subtle patterns that might not be obvious in smaller datasets.
Neural Networks Improve with Larger Datasets
Neural networks require vast amounts of training data to reach their full potential. With each additional example, the network refines its internal parameters (weights), allowing it to generalize better and handle new, unseen data more accurately. For instance, a neural network designed for image recognition improves significantly when trained on millions of labeled images, as it becomes better at distinguishing between subtle variations.
Deep Learning Models Require Vast Amounts of Data to Achieve Accuracy
Deep learning, a subset of machine learning that uses multi-layered neural networks, thrives on big data. The deeper the network (i.e., the more hidden layers it has), the more data it requires to learn effectively. These layers extract increasingly complex features from the data, enabling deep learning models to achieve high levels of accuracy in tasks like image classification, natural language processing, and speech recognition.
Big Data Enables Better Generalization and Learning of Complex Patterns
Big data helps neural networks generalize, meaning they can apply their learned knowledge to new, unseen scenarios. The diversity and volume of big data allow neural networks to learn complex patterns and relationships within the data. For example, in language models, exposure to vast amounts of text data in different contexts enables the neural network to understand nuances in meaning, syntax, and semantics, which helps the model perform well in real-world applications.
Examples of Neural Networks Powered by Big Data
Self-Driving Cars: Using Data from Sensors and Cameras to Make Decisions
Self-driving cars rely heavily on neural networks powered by big data. These cars are equipped with multiple sensors, cameras, and radar systems that collect vast amounts of real-time data about the environment, such as road conditions, traffic signals, and the presence of pedestrians or other vehicles. Neural networks process this data to make autonomous driving decisions, such as braking, steering, and accelerating, while constantly learning from new data to improve safety and performance.
Healthcare: Analyzing Large-Scale Medical Records for Diagnosis
In healthcare, neural networks are being used to analyze big data, such as electronic health records (EHRs), medical images, and genetic data, to assist in diagnosing diseases. By training on large-scale datasets of patient information, neural networks can identify patterns that might indicate the presence of specific conditions, such as cancer or heart disease, leading to earlier diagnoses and more personalized treatment plans.
E-commerce: Personalized Recommendations Based on User Behavior
E-commerce platforms use neural networks and big data to create personalized shopping experiences. By analyzing large volumes of user data—such as browsing history, purchase behavior, and product preferences—neural networks can generate personalized recommendations, helping customers find products they are more likely to buy. These systems continuously improve as they collect more data, leading to more accurate recommendations over time.
Transform Data into Intelligence with Neural Networks
#5 Creating Smart Systems with Neural Networks and Big Data
How Smart Systems Work
Smart systems, powered by the synergy between neural networks and big data, are designed to learn, adapt, and make decisions autonomously. These systems continuously process data streams, using neural networks to extract insights and adapt their behavior based on new inputs.
Systems that Continuously Learn and Adapt Through Big Data Streams
Smart systems are dynamic, constantly learning from the vast amounts of data they collect in real time. For example, a smart home system might learn the preferences of its inhabitants—such as their preferred temperature, lighting, or music—and automatically adjust settings based on past behavior. As new data is collected, the system refines its predictions and actions.
Autonomous Decision-Making (Self-Learning Without Human Intervention)
One of the defining characteristics of smart systems is their ability to make decisions without human intervention. By processing large datasets in real time and learning from past experiences, these systems can autonomously adjust their behavior. For example, a smart manufacturing system could automatically adjust machine settings based on real-time sensor data, optimizing production processes without the need for manual input.
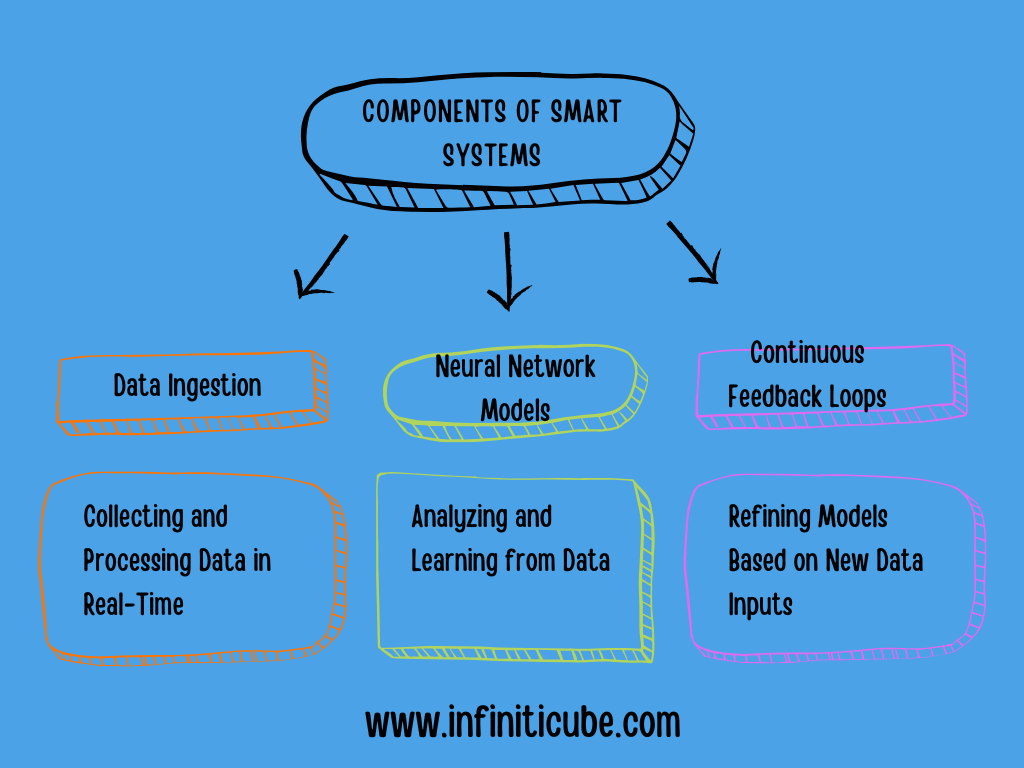
Components of Smart Systems
Data Ingestion: Collecting and Processing Data in Real-Time
Data ingestion is the first step in creating smart systems. This involves collecting data from various sources—such as IoT devices, social media, or sensors—and processing it in real-time to ensure that the system can respond quickly to new information. Efficient data ingestion pipelines are essential for smart systems that rely on fresh data to make decisions.
Neural Network Models: Analyzing and Learning from Data
Neural networks are the core of the analysis process in smart systems. Once data is ingested, neural networks process and analyze the data, identifying patterns, making predictions, and generating actionable insights. For example, in a smart energy grid, neural networks might analyze data from sensors placed throughout the grid to predict energy demand and optimize supply.
Continuous Feedback Loops: Refining Models Based on New Data Inputs
Smart systems rely on continuous feedback loops to improve their performance over time. As new data is collected, the system uses this data to retrain its models, allowing it to adapt to changing conditions. For instance, in predictive maintenance, new sensor data about machine health helps refine the system's ability to predict when maintenance is needed, improving accuracy and preventing unexpected failures.
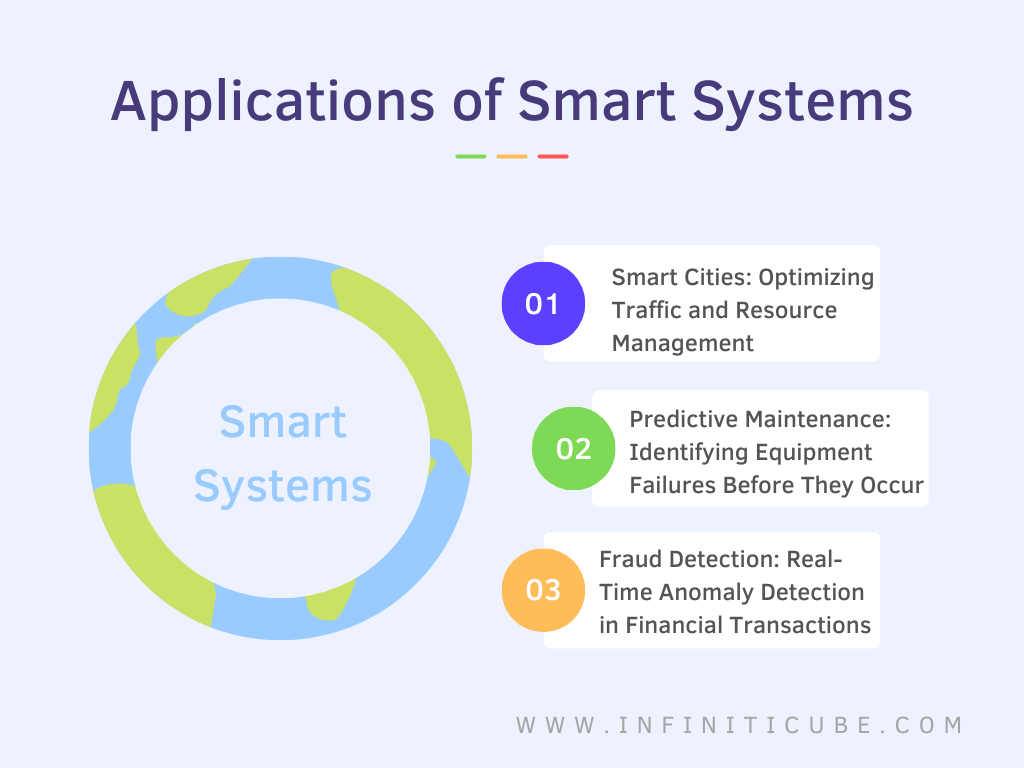
Applications of Smart Systems
Smart Cities: Optimizing Traffic and Resource Management
In smart cities, neural networks and big data are used to optimize various aspects of urban life, such as traffic flow, energy usage, and resource management. By analyzing data from traffic sensors, for example, a smart city system can predict congestion and adjust traffic signals in real-time to reduce bottlenecks, improving the overall efficiency of transportation networks.
Predictive Maintenance: Identifying Equipment Failures Before They Occur
In industrial settings, smart systems powered by neural networks can predict equipment failures before they happen, reducing downtime and maintenance costs. By analyzing data from machine sensors and historical maintenance records, these systems can detect patterns that indicate an impending failure and trigger maintenance before the issue escalates.
Fraud Detection: Real-Time Anomaly Detection in Financial Transactions
In the financial industry, smart systems are used for real-time fraud detection. Neural networks analyze large datasets of transaction records to identify unusual patterns that could indicate fraudulent activity. By continuously learning from new data, these systems can quickly adapt to new types of fraud, offering faster and more accurate fraud detection.
#6 Challenges in Combining Neural Networks with Big Data
Data Privacy and Security
One of the significant challenges in merging neural networks with big data is managing sensitive information securely.
Handling Sensitive Information in Healthcare, Finance, Etc.
In industrieslike healthcare and finance, big data often contains sensitive and personally identifiable information. For example, healthcare data might include patient records, genetic data, or treatment histories, while financial data could involve personal banking information or transaction details. Ensuring the privacy and security of this data while using it to train neural networks is critical, as breaches can lead to serious consequences, such as identity theft or legal penalties.
The Impact of GDPR and Other Privacy Regulations
With regulations such as theGeneral Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), organizations must comply with strict rules regarding data handling, storage, and usage. These regulations ensure that individuals' privacy is respected, giving them control over their data. However, adhering to these rules can complicate the process of utilizing big data for neural network training, as organizations need to balance between data accessibility and privacy protections.
Computational Challenges
The processing power required to handle both big data and neural networks is immense, presenting computational challenges.
The Need for Powerful Hardware (GPUs, TPUs) to Handle Both Big Data and Complex Models
Neural networks, particularly deep learning models, are computationally intensive, requiring specialized hardware like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) for efficient training. Coupled with the large volumes of big data, these models demand significant processing power to analyze data in real-time and make predictions.
Optimizing Storage and Processing Systems for Scalability
The sheer volume of data requires scalable storage and processing systems. Traditional data storage and processing frameworks may not suffice for big data's demands, so businesses must adopt scalable systems like distributed databases (e.g., Hadoop, Spark) and cloud computing to efficiently manage and process large datasets for neural network training.
Data Quality and Bias
For neural networks to function effectively, they need high-quality, unbiased data.
The Challenge of Cleaning and Pre-Processing Large Datasets
Big data often includes noisy, incomplete, or inconsistent data, which can degrade the performance of neural networks if not handled properly. Cleaning and pre-processing data is critical for removing errors, standardizing formats, and ensuring that the data is usable for training models. However, this process is time-consuming and resource-intensive, particularly when dealing with vast datasets.
Avoiding Bias in Data and Models, and Ensuring Fairness in AI Systems
Another challenge is avoiding bias in the datasets used to train neural networks. If the data reflects biases (such as demographic imbalances), the resulting model can perpetuate those biases, leading to unfair outcomes. For example, facial recognition systems trained on datasets disproportionately representing certain racial groups may perform poorly on underrepresented groups. Ensuring fairness in AI systems involves carefully curating diverse and representative datasets and regularly auditing models for biased behavior.
#7 Future Trends in Neural Networks and Big Data
AI and Edge Computing
One of the emerging trendsis moving neural networks closer to the data source through edge computing.
Bringing Neural Networks to Edge Devices (e.g., Smartphones, IoT Devices) for Real-Time Decision-Making
Edge computing allows neural networks to run on devices closer to the data source, such as smartphones, IoT devices, or sensors, reducing the need for sending data to centralized servers. This enables real-time decision-making in areas like autonomous vehicles, smart home systems, and industrial IoT. The combination of big data and neural networks at the edge improves latency, security, and scalability, making AI more accessible and efficient.
Reinforcement Learning with Big Data
Reinforcement learning (RL), where systems learn by interacting with their environment, is evolving with the help of big data.
How Reinforcement Learning Models Can Optimize Decisions with Continuous Data Streams
In reinforcement learning, an agent learns by receiving feedback (rewards or penalties) from its environment. When combined with big data, RL can optimize decisions by continuously learning from data streams. This approach is used in applications such as robotics (learning complex behaviors) and finance (optimizing trading strategies). As big data becomes more available, RL systems can further improve their decision-making abilities by learning from vast datasets in dynamic environments.
Federated Learning
A promising development in AI is federated learning, which addresses data privacy concerns.
Sharing and Learning from Distributed Datasets While Maintaining Data Privacy
Federated learning allows neural networks to learn from decentralized datasets located on different devices or systems without requiring data to be shared. For instance, smartphones can locally train models on user data, and then only share the model updates, not the data itself, with a central server. This method preserves user privacy while still allowing the collective power of distributed data to improve model performance, making it particularly useful in sectors like healthcare and finance.
Explainable AI (XAI)
One of the critical challenges with neural networks is their "black box" nature, which has led to the development of Explainable AI (XAI).
Efforts to Make Neural Networks More Transparent and Understandable, Especially with Big Data Models
Neural networks, particularly deep learning models, are often seen as opaque, making it difficult to understand how they arrive at specific decisions. This lack of transparency is problematic, especially in critical applications like healthcare or finance, where trust and accountability are essential. Explainable AI (XAI) focuses on making neural networks more interpretable by providing insights into how models process data and make predictions. As neural networks are increasingly used with big data, XAI will play a crucial role in ensuring that AI systems are transparent, trustworthy, and fair.
#8 Conclusion
The Ongoing Evolution of Smart Systems
Neural networks and big data are at the forefront of AI innovation, pushing the boundaries of what machines can do. As both technologies advance, their combination leads to smarter systems capable of learning, adapting, and making complex decisions with minimal human intervention. The ongoing evolution of smart systems continues to revolutionize industries by driving efficiency, accuracy, and new capabilities.
Neural Networks + Big Data = AI Powerhouse: Together, neural networks and big data create more powerful, intelligent systems. This synergy allows AI systems to learn from vast datasets, identify intricate patterns, and improve over time without manual input.
AI-Driven Future: As AI modelsand big data infrastructures evolve, we can expect more self-learning systems across industries—leading to greater automation and innovation in fields such as healthcare, finance, manufacturing, and transportation.
Key Takeaways
Synergy Between Neural Networks and Big Data: Neural networks thrive on the availability of large, diverse datasets, allowing them to achieve higher accuracy and generalization capabilities. This synergy is vital for the creation of advanced AI systems that can learn autonomously.
Continuous Improvements: The continuous development of big data infrastructure (e.g., cloud computing, data lakes) and advancements in AI models (e.g., deep learning, federated learning) will further drive the evolution of smart systems.
Smart Systems of the Future: Future smart systems will not only learn faster and better from data but also make more accurate predictions, adapt in real time, and operate at the edge (closer to where data is generated).
#9 Call to Action
Explore and Leverage Neural Networks and Big Data
As we stand on the brink of even greater advancements in AI and data science, it's essential to explore the opportunities that neural networks and big data present. For businesses, researchers, and developers alike, leveraging these technologies can create smart solutions that drive innovation, solve complex problems, and transform industries.
AI for Everyone: Whether you're in finance, healthcare, e-commerce, or any other sector, AI-powered smart systems offer solutions that can improve decision-making, streamline operations, and provide personalized experiences.
Start Small, Think Big: Begin by experimenting with neural networks and big data on a smaller scale, learning how these technologies can enhance your business or project. Over time, scale up to develop more advanced AI systems.
Final Thoughts
The combination of neural networks and big data holds immense potential for transforming industries and improving lives. From personalized healthcare to predictive maintenance and fraud detection, the possibilities are endless. By embracing this synergy, we can create smarter systems that learn, adapt, and positively impact the world. Now is the time to get involved and lead the charge into the future of AI-powered innovation.
Take the Next Step with Infiniticube
Ready to harness the power of neural networks and big data?
Start exploring how these technologies can transform your business and industry. Whether you're building smarter solutions, improving decision-making, or driving innovation, now is the time to act.
He is working with infiniticube as a Digital Marketing Specialist. He has over 3 years of experience in Digital Marketing. He worked on multiple challenging assignments.
Our newsletter is finely tuned to your interests, offering insights into AI-powered solutions, blockchain advancements, and more. Subscribe now to stay informed and at the forefront of industry developments.











 June 27, 2025
June 27, 2025
 Balbir Kumar Singh
Balbir Kumar Singh
 0
0


Leave a Reply