Neural networks are machine learning algorithms that imitate human brain processing using interconnected artificial neurons. These networks consist of layers of perceptrons, which process inputs, adjust parameters, and improve predictions over time.
Their multi-layered architecture allows them to learn complex patterns, addressing a variety of tasks. Neural networks have significantly advanced machine learning, especially through deep learning, enabling models to process complex data like images and text.
This advancement revolutionized fields such as computer vision and natural language processing, allowing machines to achieve high accuracy and outperform humans in specific tasks. They are crucial for modern AI applications, driving future innovations.
The human brain's biological neurons inspire the architecture of neural networks. In the brain, neurons are cells that process and transmit information through electrical and chemical signals. They are connected via synapses, forming a network that allows the brain to learn, adapt, and process complex patterns.
In artificial neural networks, the fundamental unit is the perceptron, which functions similarly to a biological neuron. Each perceptron receives one or more inputs, processes them using a mathematical function, and outputs a signal.
Just as biological neurons communicate and adjust their connections based on experience, artificial neurons are "trained" by adjusting their internal parameters, allowing the network to learn from data and improve its performance. The more perceptrons and layers a neural network has, the greater its capacity to model complex patterns.
Basic Architecture
A neural network comprises three main types of layers: the input layer, hidden layers, and output layer.
Input Layer: The input layerconsists of neurons that receive the raw data. Each neuron in this layer represents one feature of the input data (e.g., pixel intensity in an image, temperature in weather data). These inputs are passed to the hidden layers for processing.
Hidden Layers: Hidden layers are where most of the computational work happens. Each neuron in these layers takes the weighted inputs from the previous layer, applies an activation function, and passes the result to the next layer. The depth (number of hidden layers) and the number of neurons per layer determine the complexity and learning capacity of the network. A deep neural network, for example, has multiple hidden layers, enabling it to capture highly intricate patterns and relationships in the data.
Output Layer: The final layer is the output layer, which produces the network's prediction. For instance, in a classification task, this layer might output probabilities for each class, while in regression, it outputs a continuous value. The number of neurons in the output layer corresponds to the number of classes or the dimensionality of the output.
Activation Functions
Activation functions introduce non-linearity into a neural network, allowing it to model more complex relationships. Without non-linearity, a neural network would behave like a simple linear model, which limits its capacity to capture intricate data patterns.
Common activation functions include:
Sigmoid: Maps input values to a range between 0 and 1, making it suitable for tasks where the output is binary (e.g., yes/no). However, it can suffer from vanishing gradients during backpropagation, slowing down learning.
ReLU (Rectified Linear Unit): Outputs the input if positive, otherwise outputs zero. ReLU is widely used in deep networks due to its efficiency and ability to mitigate the vanishing gradient problem.
Tanh: Similar to sigmoid, but maps input values to a range between -1 and 1. This makes it more suitable for tasks where negative values are expected in the output.
Each activation function plays a key role in determining how the neural network processes and transforms the data as it passes through the layers.
Weights and Biases
Learning in a neural network is driven by the adjustment of weights and biases, which are the parameters that determine how each neuron processes inputs.
Weights are the parameters that scale the input data. Each input to a neuron is multiplied by a weight, which determines how important that particular input is for the neuron's output. During training, these weights are updated to minimize the error between the network's prediction and the actual output.
Biases are added to the weighted sum of inputs, allowing the network to shift the activation function and fit more complex patterns. Biases help the network make predictions even when inputs are zero.
The process of adjusting these weights and biases is guided by an algorithm called backpropagation, which calculates the error at the output layer and propagates it backward through the network. The network adjusts its weights and biases by using optimization techniques like gradient descent to minimize this error, leading to improved performance over time.
Together, weights and biases determine howneural networks transform input data into meaningful predictions, enabling them to learn complex patterns and relationships in large datasets.
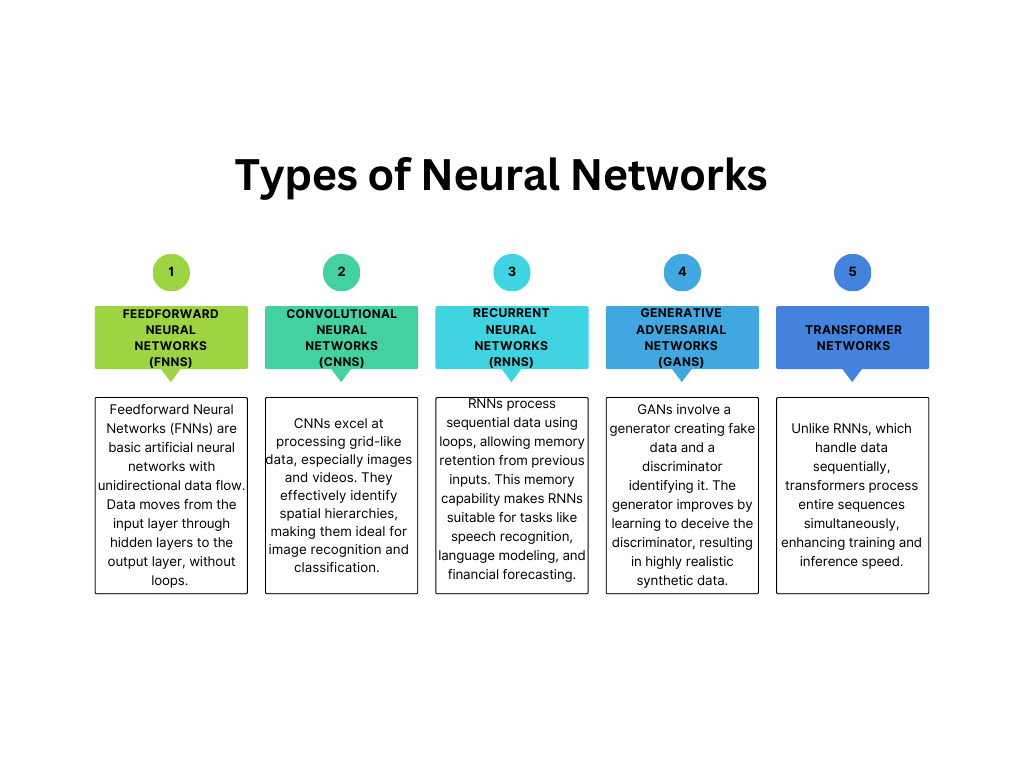
Feedforward Neural Networks (FNNs) are the simplest type of artificial neural network, where the data flows in one direction—forward—from the input layer, through the hidden layers, to the output layer. In this structure, there are no loops or cycles, and each neuron in one layer is connected only to neurons in the next layer. FNNs are mainly used for tasks like pattern recognition, classification, and regression.
Key Characteristics:
Simplicity: FNNs are easy to implement and understand, making them ideal for basic machine-learning tasks.
Limitation: While FNNs perform well on static data, they are not effective at handling sequential or time-dependent data due to the absence of memory or feedback mechanisms.
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are designed to process grid-like data, such as images or videos. They are particularly effective at identifying spatial hierarchies in data, making them the go-to choice for image recognition and classification tasks. The key innovation in CNNs is the use of convolutional layers, which apply filters to the input data to detect features like edges, textures, or patterns automatically.
Key Features:
Convolutional Layers: These layers reduce the dimensionality of the input while preserving important features, allowing CNNs to focus on the most relevant information.
Pooling Layers: Pooling further reduces the spatial dimensions, making the network more efficient.
Applications: CNNs are widely used in facial recognition, object detection, medical imaging, and even self-driving cars.
Recurrent Neural Networks (RNNs)
Recurrent Neural Networks (RNNs) are designed to handle sequential or time-series data by incorporating loops within the network. This enables RNNs to maintain a form of memory, where previous inputs can influence the current output, making them ideal for tasks involving ordered data, such as speech recognition, language modeling, and financial forecasting.
Key Features:
Recurrent Connections: RNNs have feedback loops that allow information to persist over time, making them well-suited for tasks where context or sequence matters.
Limitations: Standard RNNs struggle with long-term dependencies due to the problem of vanishing or exploding gradients during training.
LSTM & GRU: These are specialized RNN variants designed to address these limitations by introducing mechanisms to retain important information over longer sequences.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) consist of two networks—the generator and the discriminator—which work against each other. The generator creates fake data (e.g., images, text) that mimic real data, while the discriminator attempts to distinguish between real and generated data. The generator improves over time as it learns to "fool" the discriminator, leading to the creation of highly realistic synthetic data.
Key Features:
Generative Model: GANs are used to create new data that looks real, such as AI-generated artwork, deepfake videos, or synthetic medical data for research.
Adversarial Training: The competition between the generator and discriminator drives the model to improve iteratively.
Applications: GANs are widely used in fields like image generation, video synthesis, and game design, where generating new, realistic content is valuable.
Transformer Networks
Transformer networks are a recent and highly influential architecture, particularly in natural language processing (NLP). Unlike RNNs, which process data sequences step-by-step, transformers use an attention mechanism to process entire sequences in parallel, dramatically speeding up training and inference.
Key Features:
Attention Mechanism: This allows transformers to focus on different parts of a sequence simultaneously, understanding the relationships between distant words or data points in the sequence.
Scalability: Transformers can be trained on large datasets efficiently and are highly scalable, making them suitable for modern NLP tasks.
Applications: Transformers are the foundation for state-of-the-art language models like GPT (Generative Pretrained Transformer) and BERT (Bidirectional Encoder Representations from Transformers), which excel in text generation, machine translation, and sentiment analysis.
Thelearning process in neural networks revolves around the training phase, where the network adjusts its parameters to minimize prediction errors. This process typically involves two key steps: backpropagationand gradient descent.
Forward Pass: The training begins with a forward pass, where input data is passed through the network. The network processes the input through multiple layers and produces an output (prediction).
Loss Calculation: After generating an output, the network compares its prediction to the actual target (label) using a loss function, which quantifies the error. The higher the error, the worse the network's performance on that data point.
Backpropagation: In the backpropagation phase, the network calculates how much each weight and bias contributed to the error. This is done by computing the gradients—partial derivatives of the loss function concerning each weight and bias. The gradients flow backward through the network, from the output layer to the input layer, allowing the network to understand which connections need adjustment.
Gradient Descent: Using the calculated gradients, the network updates its weights and biases in small steps to minimize the loss. Gradient descent is the optimization technique used to reduce the loss by adjusting parameters. This process is repeated for many iterations (epochs) until the network learns to produce accurate predictions.
Loss Functions
Loss functions, also known as cost functions, measure the discrepancy between the predicted output and the true output. The goal of training a neural network is to minimize this loss, ensuring that the model's predictions closely match the actual data. Different types of tasks use different loss functions:
Mean Squared Error (MSE): Commonly used for regression tasks, MSE calculates the average squared difference between predicted and actual values.
Cross-Entropy Loss: Frequently used for classification tasks, cross-entropy measures the dissimilarity between the predicted probability distribution and the actual class distribution.
The loss function guides the backpropagation process, ensuring the network learns from its mistakes by adjusting its parameters in the right direction.
Optimization Techniques
While gradient descent is the foundational method for optimization, there are several variants designed to improve learning speed and accuracy:
Stochastic Gradient Descent (SGD): In traditional gradient descent, the entire dataset is used to compute gradients, which can be computationally expensive. SGD addresses this by updating the weights after each data point or mini-batch, speeding up the learning process. However, the updates can be noisy, making convergence slower or less stable.
Adam Optimizer: Adam (Adaptive Moment Estimation) is one of the most popular optimizers in deep learning. It combines the benefits of both momentum-based optimizers and adaptive learning rates. Adam dynamically adjusts the learning rate for each parameter based on the past gradients, making it faster and more efficient at finding the optimal weights. This optimizer is especially useful when dealing with large, complex datasets.
Each optimizer aims to minimize the loss in a way that balances learning speed and accuracy, helping the network to converge efficiently during training.
Overfitting and Regularization
One of the key challenges in training neural networks is overfitting, where the model learns to perform extremely well on the training data but fails to generalize to new, unseen data. Overfitting occurs when the network becomes too complex, learning noise and irrelevant patterns from the training set.
Regularization techniques are used to prevent overfitting and improve the model's ability to generalize:
Dropout: Dropout is a technique where, during training, random neurons are "dropped" or deactivated. This forces the network to learn redundant representations, making it more robust and preventing it from relying too heavily on any single neuron. At test time, all neurons are active, but the model benefits from the improved generalization learned during training.
Early Stopping: Early stopping is a simple yet effective technique where training is halted once the model's performance on a validation set begins to deteriorate. This prevents the network from overfitting by ensuring it doesn’t continue to learn unnecessary details from the training data.
L2 Regularization (Weight Decay): L2 regularization penalizes large weights by adding a penalty term to the loss function, encouraging the model to keep weights small and thus preventing overfitting.
By incorporating these regularization techniques, neural networks can strike a balance between learning the training data and being able to generalize to new, unseen data, which is crucial for real-world applications.
V. Applications of Neural Networks in Modern Machine Learning
Image and Video Processing
Neural networks, particularly Convolutional Neural Networks (CNNs), are at the core of modern computer vision applications. They have transformed how machines interpret visual data, enabling them to recognize objects, people, and even complex patterns within images and videos.
Facial Recognition: CNNs are widely used in facial recognition systems to identify and verify individuals. These systems are employed in security, law enforcement, and even social media platforms, where they tag users in photos automatically.
Autonomous Vehicles: Self-driving cars rely heavily on neural networks to process vast amounts of video data from their surroundings. CNNs help these vehicles detect and classify objects such as pedestrians, other cars, and road signs, allowing for safe navigation in real-time.
Medical Imaging: Neural networks are also crucial in medical fields, such as radiology, where they assist in diagnosing diseases from medical images like X-rays, MRIs, and CT scans. They can detect tumors, fractures, or abnormalities with high accuracy, sometimes surpassing human experts.
Natural Language Processing (NLP)
Neural networks, especially Transformer models, have revolutionized the way machines understand and generate human language. These advances have led to significant improvements in various NLP applications:
Chatbots and Virtual Assistants: Models like GPT (Generative Pretrained Transformer) enable chatbots and virtual assistants, such as Siri, Alexa, and Google Assistant, to understand user queries and provide intelligent responses in natural language.
Language Models: Neural networks power sophisticated language models that can generate human-like text, translate languages, summarize long documents, and perform sentiment analysis. For example, models like GPT-4 and BERT excel in tasks like text completion, classification, and question-answering.
Translation Systems: Neural networks have improved machine translation systems, such as Google Translate, making them more accurate and fluent by capturing the nuances of language and context across different languages.
Recommender Systems
Neural networks play a vital role in personalizing user experiences on platforms like Netflix, Amazon, and Spotify. These recommender systems analyze vast amounts of user data to suggest relevant content, products, or services based on individual preferences.
Content Recommendations: By analyzing users' viewing habits, neural networks help Netflix recommend movies or TV shows. Similarly, Spotify uses neural networks to suggest music based on a user’s listening history and preferences.
Product Recommendations: E-commerce platforms like Amazon use neural networks to predict which products a customer is likely to buy, personalizing the shopping experience and increasing user engagement. The models consider user behavior, past purchases, and product similarities to make accurate predictions.
Healthcare
Neural networks are driving innovation in healthcare, with applications ranging from diagnostics to drug discovery. Their ability to analyze large datasets and identify patterns has opened new possibilities for improving patient care and treatment outcomes.
Disease Prediction: Neural networks can analyze electronic health records and genetic data to predict the onset of diseases like diabetes, heart disease, or cancer. These models help doctors make more informed decisions and provide early interventions.
Medical Imaging: In addition to detecting diseases in images, neural networks are used to track disease progression over time. For example, they can measure tumor growth in cancer patients or monitor changes in the brain related to neurodegenerative diseases.
Drug Discovery: Neural networks are accelerating the process of drug discovery by simulating molecular interactions and predicting how new drugs will affect the body. This can significantly reduce the time and cost involved in bringing new medications to market.
Finance
In the financial industry, neural networks are increasingly being used for tasks that require fast, accurate, and complex decision-making, improving everything from fraud detection to portfolio management.
Fraud Detection: Neural networks excel at identifying patterns in transaction data that might indicate fraudulent activities. Financial institutions use these models to detect unusual behavior in real-time, preventing fraudulent transactions before they occur.
Algorithmic Trading: High-frequency trading algorithms powered by neural networks analyze market data and execute trades within milliseconds. These models can predict market trends and make profitable trading decisions based on patterns that are difficult for humans to detect.
Risk Analysis: Neural networks are also used in credit scoring and risk analysis, helping financial institutions assess the likelihood of loan defaults or other financial risks. By analyzing customer data, these models provide more accurate risk assessments than traditional methods.
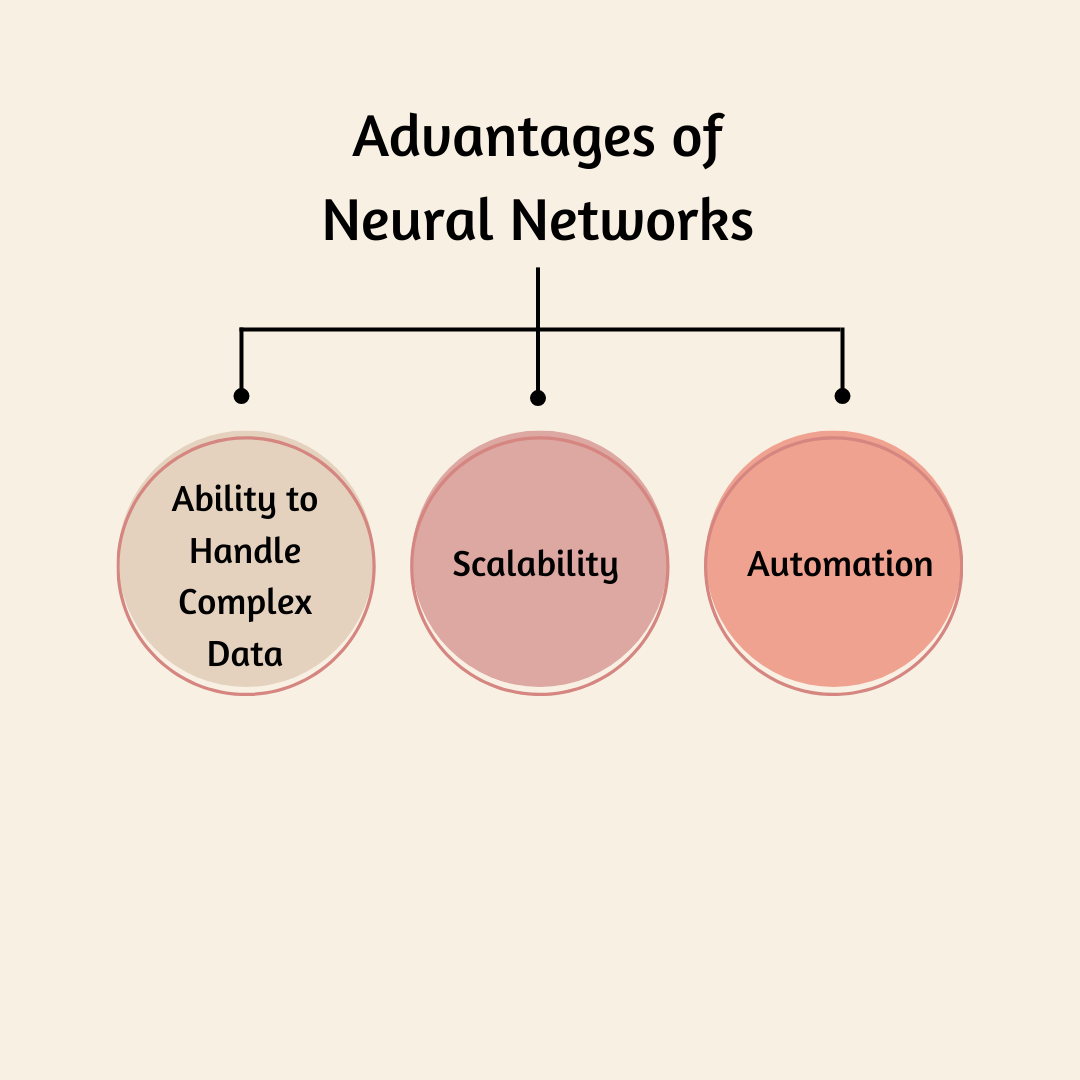
VI. Advantages of Neural Networks
Ability to Handle Complex Data
One of the most significant advantages of neural networks is their capacity to handle complex, non-linear data. Traditional machine learning models, such as linear regression, often struggle with datasets that contain intricate patterns or relationships. Neural networks, however, excel in learning and modeling these complexities due to several key factors:
Non-Linearity: The use of activation functions like ReLU and sigmoid allows neural networks to introduce non-linearity into the model, enabling them to capture and model complex, multi-dimensional data relationships that are not easily separable in a linear space.
Multi-layer Processing: With the ability to stack multiple hidden layers, neural networks can break down complex tasks into smaller, more manageable sub-tasks. This layered architecture enables the network to extract more abstract and meaningful patterns as data moves through the layers, making them highly effective for tasks like image classification, natural language understanding, and more.
Feature Hierarchy: In tasks like image processing, neural networks, especially convolutional neural networks (CNNs), create hierarchical representations of data. This allows them to recognize low-level features such as edges in the early layers, while the deeper layers capture higher-level features like objects or faces, making them effective at understanding complex visual data.
Scalability
Neural networks are highly scalable, making them adaptable to handle large-scale datasets across various domains, including finance, healthcare, and retail. This scalability offers several benefits:
Data-Driven Improvements: Neural networks generally perform better as the size of the dataset increases. While traditional algorithms may struggle with large datasets, neural networks can take advantage of big data, learning from large amounts of information and improving accuracy and robustness with more training data.
Parallel Computing: The architecture of neural networks, particularly deep learning models, is well-suited to leverage parallel computing frameworks such as GPUs and TPUs. These hardware accelerators significantly speed up the training process, making neural networks capable of scaling across massive datasets in reasonable time frames.
Versatility Across Domains: Whether dealing with images, text, time-series data, or unstructured data, neural networks are versatile and can be adapted to various domains. This scalability makes them suitable for applications like autonomous driving (which processes real-time data from multiple sensors) and natural language processing (handling large corpora of text data).
Automation
One of the most transformative advantages of neural networks is their ability to reduce the need for manual feature engineering, a task that traditionally required domain expertise and significant effort. Neural networks can automate the process of feature extraction and learning from raw data, which leads to several key benefits:
End-to-End Learning: Neural networks can learn from raw data without requiring domain-specific feature extraction techniques. This ability allows them to automate the process of identifying patterns in complex datasets. For example, in image recognition tasks, neural networks can process raw pixel data and automatically learn distinguishing features like shapes, textures, and colors, which traditional models would require manual input to define.
Feature Discovery: Deep neural networks, especially in deep learning, are excellent at discovering latent features that might be difficult for humans to identify. By automating feature learning, neural networks reduce human bias and can uncover hidden relationships in data, leading to improved accuracy and generalization in predictive models.
Reduction of Human Effort: The automation capabilities of neural networks significantly decrease the amount of manual effort needed to prepare and pre-process data. This is particularly beneficial in fields like speech recognition, natural language processing, and computer vision, where raw data can be complex and voluminous.
VII. Challenges and Limitations of Neural Networks
Data Dependency
One of the primary challenges with neural networks is their reliance on vast amounts of labeled data for training. Unlike traditional machine learning models, which can perform well on relatively small datasets, neural networks—especially deep learning models—require extensive datasets to perform optimally.
Training Requirements: Neural networks improve their accuracy by learning from large datasets. The more data they have, the better they become at recognizing patterns and making predictions. However, collecting and labeling sufficient data can be expensive, time-consuming, and impractical, especially for specialized applications like medical imaging or scientific research.
Quality of Data: The performance of a neural network is highly dependent on the quality of the data. Poor quality or biased data can lead to inaccurate or unfair outcomes. Even when vast amounts of data are available, they must be cleaned and processed to ensure that the network learns relevant patterns.
Generalization Issues: Neural networks trained on limited or specific datasets may struggle to generalize to new, unseen data. This issue can arise when the training data does not adequately represent the real-world scenarios the model will face in deployment, leading to overfitting and reduced performance.
Computational Resources
Training neural networks, particularly deep learning models with many layers and parameters, requires significant computational power. The need for specialized hardware and high computational demand presents several limitations:
High Demand for GPUs/TPUs: Neural networks, especially those involving complex architectures like Convolutional Neural Networks (CNNs) or Transformer models, require GPUs (Graphics Processing Units) or TPUs (Tensor Processing Units) for efficient training. These hardware accelerators are necessary for parallel processing, making the training of large-scale models feasible. However, they are expensive and require specialized infrastructure, which can be a barrier for smaller companies or researchers without access to such resources.
Energy Consumption: Training deep neural networks consumes significant amounts of energy, especially for large-scale models like GPT or BERT. This has raised concerns about the environmental impact of AI research and the sustainability of training large-scale models, given the high electricity usage involved in the process.
Time-Consuming: Even with access to GPUs, training large neural networks can take hours, days, or even weeks, depending on the complexity of the model and the size of the dataset. This slows down the iteration process and increases the cost of experimentation and innovation in the field of neural networks.
Explainability
Neural networks are often criticized for their lack of interpretability, which is referred to as the "black box" problem. This limitation makes it difficult to understand how a neural network arrives at a particular decision or prediction.
Complex Decision-Making: Neural networks, particularly deep learning models, involve numerous layers and millions of parameters, making it challenging to trace how inputs are transformed into outputs. This lack of transparency is especially problematic in critical applications like healthcare, finance, and law, where understanding the decision-making process is essential.
Trust and Accountability: The inability to explain neural network decisions can erode trust in AI systems, especially when they are used in sensitive or high-stakes applications. For instance, in medical diagnosis or loan approval systems, stakeholders need to understand why a certain decision was made, especially if it affects people's lives or financial well-being.
Efforts to Improve Explainability: Researchers are actively working on methods to improve the interpretability of neural networks, such as attention mechanisms or explainable AI (XAI) frameworks. However, balancing performance and explainability remains a key challenge in deploying neural networks for real-world applications.
Ethical Concerns
Neural networks are prone to ethical challenges, especially when biases in the training data lead to unfair or harmful outcomes. These ethical concerns arise because of the complex interplay between data, model architecture, and deployment context.
Bias in Training Data: If the data used to train neural networks contains biases, the models can learn and perpetuate these biases. For example, facial recognition systems trained on biased datasets may perform worse on minority groups, leading to discriminatory outcomes in law enforcement or hiring processes. Similarly, language models may generate biased or offensive content if trained on unfiltered internet data.
Fairness in Sensitive Applications: In domains like criminal justice, hiring, and lending, neural networks are being used to make decisions that significantly impact individuals' lives. If these models reflect societal biases, they could reinforce existing inequalities. Ensuring fairness, transparency, and accountability in such applications is an ongoing challenge.
Ethical Frameworks and Regulations: As neural networks are deployed in more sensitive applications, there is a growing need for ethical frameworks and regulations to ensure responsible use. Policymakers and researchers are focusing on creating guidelines to prevent misuse, but addressing these concerns remains a complex, ongoing process.
VIII. The Future of Neural Networks
Neural Networks and AI
Neural networks are not just a driving force behind modern machine learning; they are also leading the push towards Artificial General Intelligence (AGI), the idea of creating systems that can perform any intellectual task that a human can do. While current AI systems are specialized and designed to excel in specific tasks (known as narrow AI), the advancements in neural networks bring us closer to developing more general AI systems.
From Narrow AI to AGI: Today’s neural networks excel in specific applications like image recognition, language translation, and recommendation systems, but these models often lack the flexibility to perform a broad range of tasks outside of their training. However, research into more sophisticated architectures—like transformers and self-supervised learning—is paving the way for models that can generalize better across tasks, potentially inching towards AGI.
Self-Supervised and Unsupervised Learning: The future of neural networks is likely to involve a greater focus on models that require less human-labeled data. Self-supervised learning, where the model learns to predict parts of the data without explicit labels, is already showing promise in models like GPT and BERT. This shift could help overcome the data dependency problem and push AI closer to general intelligence.
Ethical and Societal Impacts: As neural networks evolve toward AGI, ethical questions about their role in society will become more pressing. Issues like bias, accountability, and control over AI systems will need to be addressed as these models take on more autonomous and decision-making roles.
Quantum Neural Networks
The intersection of quantum computing and neural networks represents an exciting frontier in AI development. While still in the experimental stage, quantum neural networks (QNNs) offer the potential for faster and more efficient processing compared to classical neural networks.
Quantum Speedup: Quantum computers leverage the principles of quantum mechanics, like superposition and entanglement, to perform complex computations in parallel. QNNs could exploit this speedup for tasks such as optimization and large-scale data analysis, solving problems that are computationally infeasible for classical computers.
Challenges and Opportunities: While promising, quantum computing is still in its infancy, with many technical challenges to overcome, such as error rates and qubit stability. Nevertheless, researchers are optimistic that quantum neural networks will unlock new levels of performance, especially in fields requiring vast computational power, such as climate modeling, cryptography, and drug discovery.
Quantum Neural Network Algorithms: As quantum hardware continues to evolve, so too will the algorithms that power QNNs. These algorithms will need to be designed to take full advantage of quantum principles while being adaptable to classical deep learning methods, making the collaboration between quantum computing and neural networks a potential breakthrough in the coming decades.
Neural Architecture Search (NAS)
The manual design of neural networks is a time-consuming and resource-intensive process. Neural Architecture Search (NAS) is a new field that aims to automate the design of neural network architectures using machine learning.
Automated Model Creation: NAS uses algorithms to automatically explore different neural network architectures to find the best model for a given task. This approach eliminates the need for human intuition in model design and can discover architectures that outperform manually created models.
Efficiency and Performance: With NAS, researchers have the potential to discover optimized architectures that are both more efficient and more accurate. For example, NAS has already been used to develop models that perform better on tasks like image classification and object detection while using fewer computational resources.
Widespread Adoption: As NAS becomes more accessible and refined, it is expected to democratize deep learning, allowing more organizations to implement cutting-edge neural networks without the need for deep expertise in model architecture. This trend will accelerate the adoption of AI across industries and domains.
Continual Learning
One of the current limitations of neural networks is catastrophic forgetting, where a model forgets previously learned information when trained on new tasks. Continual learning aims to solve this by developing neural networks that can learn new tasks while retaining prior knowledge.
Overcoming Catastrophic Forgetting: Traditional neural networks tend to overwrite previously learned weights when training on new data, causing them to forget old information. Continual learning techniques, such as Elastic Weight Consolidation (EWC) and progressive neural networks, are designed to prevent this by maintaining a balance between learning new tasks and retaining old knowledge.
Adaptive AI Systems: Continual learning will enable the development of adaptive AI systems capable of learning over time without needing to be retrained from scratch. This would be particularly valuable in dynamic environments where new data and tasks emerge frequently, such as robotics, autonomous driving, and personalized medicine.
Real-World Applications: In fields like healthcare and finance, where data is constantly evolving, continual learning will allow AI systems to stay updated with the latest information without discarding past knowledge. For example, an AI system in healthcare could learn about new diseases while retaining the ability to diagnose older conditions.
Unlock the Future with Infiniticube’s Advanced AI and Quantum Solutions!
Infiniticube offers cutting-edge solutions for businesses seeking to harness the power of advanced technology. From Neural Networks and AI-driven models to Quantum Computing and Continual Learning systems, we help organizations unlock new possibilities in automation, data analysis, and innovation. Our team specializes in Neural Architecture Search (NAS) to design optimized AI models tailored to your needs and ensure scalability and performance across industries like healthcare, finance, and more.
Ready to future-proof your business with Infiniticube?
Contact us today to explore custom solutions and take your operations to the next level!
He is working with infiniticube as a Digital Marketing Specialist. He has over 3 years of experience in Digital Marketing. He worked on multiple challenging assignments.
Our newsletter is finely tuned to your interests, offering insights into AI-powered solutions, blockchain advancements, and more. Subscribe now to stay informed and at the forefront of industry developments.












 June 27, 2025
June 27, 2025
 Balbir Kumar Singh
Balbir Kumar Singh
 0
0


Leave a Reply