Machine learning, a subset of AI, allows computers to learn from data without explicit programming. It uses algorithms to identify patterns and make predictions.
Deep learning, a specialized branch of machine learning, employs multi-layered neural networks to process vast amounts of unstructured data. This approach mimics human brain functions, excelling in complex tasks like image recognition and natural language processing.
Deep learning has transformed AI, enhancing computer capabilities to interact with the world. It supports technologies such as autonomous driving and voice assistants, proving essential in industries like healthcare and financefor driving innovation and efficiency.
Why Learn Deep Machine Learning?
Deep machine learning powers transformative AI technologies across various industries, enhancing everyday life. Deep learning skills make you a valuable asset in tech. The demand for these skills is increasing, with roles like AI engineer and data scientist in high demand.
Opportunities exist in healthcare, finance, robotics, and more, placing you at the forefront of AI innovation. Continuous advancements in deep learning techniques ensure ongoing learning and career growth in this evolving field.
Algorithms are the core of machine learning. They are a set of rules or instructions given to a computer to help it learn patterns from data. Machine learning algorithms are designed to identify relationships within data and make predictions or decisions without human intervention. Examples include decision trees, support vector machines, and neural networks.
2. Models:
A model is the output of a machine learning algorithmapplied to data. It essentially represents the learned patterns and relationships within the data. For example, a model trained to recognize images of cats and dogs will use its learned patterns to predict whether a new image is a cat or a dog. Models are evaluated based on their ability to generalize and perform accurately on unseen data.
3. Data:
Data is the foundation of machine learning. It consists of the information fed into algorithms to learn patterns and make predictions. Data can be structured (like tables in a database) or unstructured (like images, videos, and text). The quality and quantity of data significantly influence the performance of machine learning models.
4. Training:
Training is the process where the machine learning algorithm learns from data. During training, the algorithm adjusts its parameters to minimize prediction errors. This process involves feeding the algorithm a set of training data and allowing it to learn patterns and relationships within that data.
5. Testing:
Testinginvolves evaluating the performance of a trained model on new, unseen data, called the test set. The goal is to assess how well the model generalizes to new data outside the training set. The test set helps determine the model's accuracy and reliability before it is deployed for real-world applications.
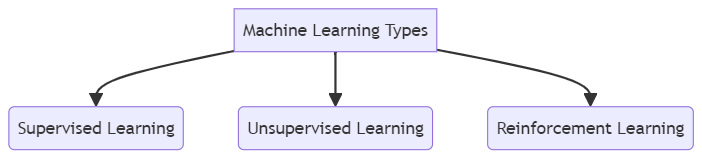
Overview of Machine Learning Types:
1. Supervised Learning:
In supervised learning, the algorithm is trained on labeled data, which means the input data is paired with the correct output. The model learns to map inputs to the proper outputs by adjusting its parameters based on the training data. Common applications include classification (e.g., email spam detection) and regression (e.g., predicting house prices).
2. Unsupervised Learning:
Unsupervised learning involves training algorithms on data without labeled responses. The algorithm tries to learn the patterns and structure of the data on its own. It is often used for clustering (grouping similar data points) and dimensionality reduction (reducing the number of variables in the data). Examples include customer segmentation and anomaly detection.
3. Reinforcement Learning:
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with its environment. The agent receives rewards or penalties based on its actions and learns to maximize cumulative rewards over time. This approach is commonly used in robotics, game-playing, and autonomous systems, such as self-driving cars.
Introduction to Neural Networks
What Are Neural Networks?
Neural networks are a series of algorithms that mimic the human brain’s structure and function, allowing computers to recognize patterns, classify data, and make decisions. They comprise interconnected nodes, or "neurons," organized into layers. Neural networks are at the heart of deep learning and have enabled breakthroughs in image recognition, natural language processing, and more.
Key Components of Neural Networks:
1. Neurons (Nodes):
Neurons are the basic units of a neural network. Each neuron receives inputs, processes them using an activation function, and produces an output that is passed to the next layer of neurons. Neurons are inspired by biological neurons in the human brain and are connected in a network to transmit information.
2. Layers:
Input Layer:
The input layer is the first layer of a neural network that receives the initial data. Each neuron in this layer represents a feature or variable from the input data.
Hidden Layers:
Hidden layers are intermediate layers between the input and output layers. They perform computations and transformations on the data received from the input layer. Deep neural networks have multiple hidden layers, allowing them to learn complex patterns in data.
Output Layer:
The output layer produces the final result of the neural network’s computations. In a classification task, for example, the output layer might contain neurons representing different classes, with the most activated neuron indicating the predicted class.
3. Activation Functions:
Activation functions determine whether a neuron should be activated or not, based on the weighted sum of inputs it receives. They introduce non-linearity into the network, allowing it to learn and model complex relationships. Common activation functions include:
ReLU (Rectified Linear Unit): Outputs the input directly if it is positive; otherwise, it outputs zero. It is widely used due to its simplicity and effectiveness in deep learning.
Sigmoid: Outputs values between 0 and 1, making it useful for probability-based predictions.
Tanh (Hyperbolic Tangent): Outputs values between -1 and 1, useful for centered data around zero.
Softmax: Used in the output layer for multi-class classification problems, it converts outputs into probabilities that sum to one.
By understanding these fundamentals, beginners can build a strong foundation in machine learning, preparing them to explore more advanced topics such as deep learning and neural networks.
The Evolution from Machine Learning to Deep Learning
Differences Between Traditional Machine Learning and Deep Learning:
Feature Engineering vs. Automatic Feature Extraction:
Traditional Machine Learning: In traditional machine learning, feature engineering is crucial. Data scientistsmanually select and transform input variables (features) to help the algorithm learn the task. This process requires domain knowledge and can be time-consuming.
Deep Learning: Deep learning models automatically learn and extract features from raw data, reducing the need for manual feature engineering. By stacking multiple layers of neurons, deep learning models can learn complex representations directly from the data.
Model Complexity:
Traditional Machine Learning: Traditional models, such as linear regression or decision trees, usually involve simpler algorithms with a limited capacity to capture highly complex patterns. They perform well with structured data and when the relationships in the data are relatively straightforward.
Deep Learning: Deep learning models use neural networks with many layers (hence “deep”). These models have a much greater capacity to capture intricate patterns and relationships, making them suitable for complex tasks like image recognition, speech processing, and natural language understanding.
Data Requirements:
Traditional Machine Learning: These models often perform well with smaller datasets and require less computational power. However, they may struggle with high-dimensional data like images or videos.
Deep Learning: Deep learning thrives on large volumes of data and typically requires substantial computational resources (e.g., GPUs) for training. More data enables deep learning models to improve accuracy and generalize new inputs.
Performance on Unstructured Data:
Traditional Machine Learning: Typically more effective with structured data (e.g., tables, spreadsheets). Pre-processing of unstructured data (e.g., text, images) is usually needed.
Deep Learning: Exceptionally effective with unstructured data, such as images, text, and audio. Neural networks automatically learn from raw data, making them highly versatile across various applications.
How Deep Learning Mimics the Human Brain's Neural Structure:
Deep learning models are inspired by the human brain's neural networks, consisting of neurons and synapses. In a neural network:
Neurons (Nodes): Represent individual processing units that receive inputs, perform computations, and pass outputs to other neurons.
Layers: Neural networks are organized into layers: an input layer, one or more hidden layers, and an output layer.
Connections (Weights): Neurons are connected by weights that determine the strength and influence of each input. These weights are adjusted during training to minimize errors in predictions.
The architecture of deep neural networks resembles the hierarchical structure of the human brain, where information is processed through multiple layers, each layer learning increasingly abstract features. For example, in image recognition, lower layers might learn edges and textures, while deeper layers recognize shapes and objects.
Deep Learning Architectures
Explanation of Deep Neural Networks (DNNs):
Deep Neural Networks (DNNs) are neural networks with multiple hidden layers between the input and output layers. These additional layers allow the network to model complex, non-linear relationships within the data. The depth of the network refers to the number of layers, and more layers generally mean the network can learn more intricate patterns. Key aspects of DNNs include:
Layer Stacking: Layers are stacked sequentially, with each layer learning from the previous one.
Backpropagation: A method used to update the weights of the network by propagating the error from the output back through the network.
Non-Linearity: Activation functions (like ReLU or sigmoid) introduce non-linearity, enabling the network to learn from a wide range of patterns.
Overview of Common Architectures:
Convolutional Neural Networks (CNNs):
Purpose: Primarily used for processing grid-like data such as images and videos. They excel in tasks like image classification, object detection, and image segmentation.
Key Features:
Convolutional Layers: Apply filters to the input data to detect features like edges, textures, and shapes.
Pooling Layers: Reduce the spatial dimensions of the data, retaining the most important features while reducing computational load.
Fully Connected Layers: Connect every neuron in one layer to every neuron in the next, typically used at the end of the network for classification.
Advantages: Efficient at recognizing spatial hierarchies and patterns, and require fewer parameters compared to fully connected networks, making them less prone to overfitting.
Recurrent Neural Networks (RNNs):
Purpose: Designed for sequential data, such as time series, text, or speech. They are used in applications like language modeling, translation, and speech recognition.
Key Features:
Recurrent Connections: Unlike feedforward networks, RNNs have loops that allow information to persist across time steps, making them suitable for sequential data.
Hidden States: Maintain a ‘memory’ of previous inputs, which influences the current output.
Variants:
Long Short-Term Memory (LSTM): A type of RNN that mitigates issues with learning long-range dependencies by using gates to control the flow of information.
Gated Recurrent Unit (GRU): A simpler variant of LSTM that also addresses the vanishing gradient problem.
Advantages: Effective at handling time dependencies and sequences in data, crucial for tasks involving context or order.
Generative Adversarial Networks (GANs):
Purpose: Used for generating new data samples that resemble the training data, such as images, music, or text. They are popular in creative fields and for tasks like image generation, style transfer, and data augmentation.
Key Features:
Generator: Produces fake data samples by learning to map random noise to data distributions.
Discriminator: Evaluates whether the generated data is real or fake, essentially a classifier.
Adversarial Training: The generator and discriminator are trained together in a zero-sum game, where the generator tries to fool the discriminator, and the discriminator tries not to be fooled.
Advantages: Capable of producing highly realistic synthetic data, and have been instrumental in advancing fields like image synthesis and video game development.
Deep learning architectures continue to evolve, with new models and techniques being developed to address specific challenges and improve performance across a wide range of applications. Understanding these architectures provides a piece of foundational knowledge for anyone looking to explore the field of deep machine learning.
Chapter 3: Key Components of Deep Machine Learning
Layers of a Neural Network
Neural networks are composed of layers, each serving a specific role in processing data and learning from it. Understanding the structure and function of these layers is fundamental to grasping how deep learning models operate.
1. Input Layer:
Role: The input layer is the first layer of the network that receives the raw data. Each neuron in this layer represents one feature of the input data. For example, in image recognition, the input layer neurons might represent pixel values.
Function: It acts as a conduit for passing input data to the subsequent layers. This layer does not perform any computations; its purpose is to hold the data in a format that the network can process.
2. Hidden Layers:
Role: Hidden layers are the intermediate layers between the input and output layers. These layers are responsible for the core processing of the neural network.
Function:
Feature Extraction and Transformation: Hidden layers perform complex transformations on the input data, extracting hierarchical features that are critical for making accurate predictions.
Layer Stacking: Multiple hidden layers allow the network to learn increasingly abstract features. For example, in image recognition, early hidden layers might learn to detect edges, while deeper layers might recognize shapes, and even deeper layers might identify complex objects.
Activation Functions: Each hidden layer usually includes an activation function that introduces non-linearity, enabling the network to model complex patterns.
3. Output Layer:
Role: The output layer is the final layer of the neural network that produces the model's predictions.
Function:
Generating Predictions: The neurons in the output layer represent the predicted output, such as a class label in classification tasks or a numerical value in regression tasks.
Activation Functions: The output layer often uses a specific activation function that suits the task. For instance, a softmax activation is used for multi-class classification to produce probability distributions over the classes.
Role and Function of Each Layer:
Input Layer: Prepares and passes data to the network.
Hidden Layers: Extract and refine features, transform data through nonlinear functions, and enable the network to learn complex patterns.
Output Layer: Produces the final prediction or decision of the network.
Activation Functions
Activation functions are critical components in neural networks, as they introduce non-linearity into the model, enabling it to learn and represent complex patterns. Without activation functions, a neural network would behave like a linear model, unable to handle non-linear decision boundaries.
Introduction to Activation Functions and Their Purpose:
Purpose: Activation functions determine whether a neuron should be activated or not, based on the weighted sum of inputs passed through it. This decision introduces the ability of the network to solve complex tasks by learning intricate data patterns.
Non-Linearity: By applying a non-linear transformation, activation functions enable the neural network to approximate complex functions, essential for tasks like image recognition, language processing, and more.
Common Activation Functions:
ReLU (Rectified Linear Unit):
Purpose: Introduces non-linearity while maintaining simplicity. ReLU is computationally efficient and reduces the likelihood of vanishing gradient problems compared to other functions.
Use Case: Commonly used in hidden layers of deep neural networks.
Sigmoid:
Purpose: Maps input values to a range between 0 and 1, making it useful for binary classification tasks.
Use Case: Typically used in the output layer of binary classification models. However, it can suffer from vanishing gradients during training.
Tanh (Hyperbolic Tangent):
Purpose: Maps input values to a range between -1 and 1, centering the output. It tends to work better than the sigmoid in hidden layers due to its zero-centered output.
Use Case: Often used in hidden layers, especially when negative values are important.
Softmax:
Purpose: Converts logits into probabilities, ensuring the sum of outputs equals 1, which is ideal for multi-class classification tasks.
Use Case: Typically used in the output layer of classification models to handle multiple classes.
Optimization and Loss Functions
Optimization and loss functions are essential for training neural networks effectively. They work together to adjust the model's weights to minimize errors and improve predictions.
What Are Loss Functions, and Why Are They Important?
Loss Functions: A loss function measures the difference between the predicted output and the actual target values. It quantifies the model's error, guiding the optimization process.
Importance: The choice of loss function affects how well the model learns. A well-chosen loss function helps the model converge faster and achieve better accuracy.
Examples:
Mean Squared Error (MSE): Commonly used for regression tasks, measuring the average squared difference between predicted and actual values.
Cross-Entropy Loss: Widely used for classification tasks, penalizing the model heavily when the predicted probabilities deviate from the actual classes.
Overview of Optimization Algorithms:
Gradient Descent:
Concept: Gradient descent is an iterative optimization algorithm used to minimize the loss function by adjusting the model’s weights. It works by calculating the gradient (partial derivative) of the loss function for each weight and updating the weights in the opposite direction of the gradient.
Variants:
Batch Gradient Descent: Uses the entire dataset to compute gradients, which can be slow for large datasets.
Stochastic Gradient Descent (SGD): Uses a single data point at each iteration, providing faster updates but more noisy progress towards the minimum.
Mini-Batch Gradient Descent: A compromise between batch and SGD, balancing speed and accuracy, using a small subset of data points at each step.
Adam (Adaptive Moment Estimation):
Concept: Adam combines the advantages of two other popular optimization algorithms: AdaGrad (which adapts the learning rate for each parameter) and RMSProp (which uses moving averages of the squared gradients to scale the learning rate). Adam maintains two moving averages, one for the gradients and one for their squared values.
Advantages:
Adaptive Learning Rates: Adam adjusts the learning rate dynamically for each parameter, making it robust to different data types.
Fast Convergence: Typically converges faster than vanilla gradient descent due to its adaptive nature.
Use Case: Widely used in deep learning due to its efficiency and good performance on various tasks.
By understanding these key components—layers, activation functions, and optimization algorithms—you gain a solid foundation in the mechanics of deep machine learning. These elements work together to enable deep learning models to learn complex patterns, adjust based on feedback, and ultimately make accurate predictions on new data.
Training a deep learning model is a systematic process that involves several key steps to ensure that the model learns effectively from the data. The goal of training is to develop a model that generalizes well to new, unseen data by minimizing the difference between its predictions and the actual target values.
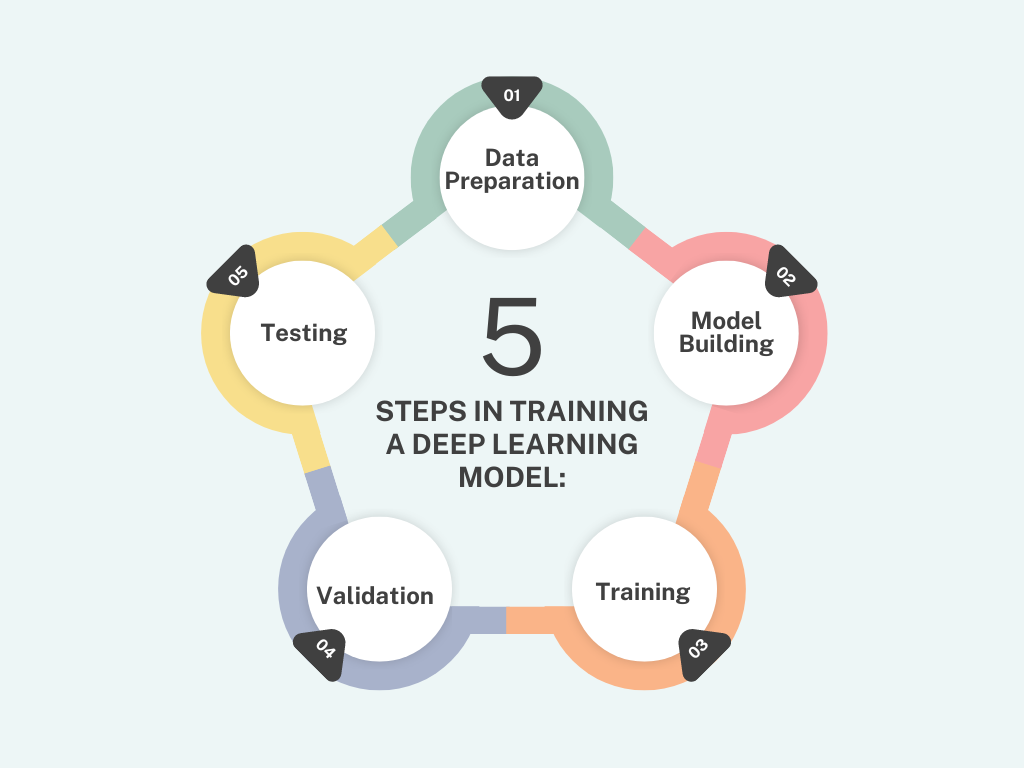
Overview of the Training Process: The training process of a deep learning model involves iteratively adjusting the model's parameters (weights) to improve its performance. Here’s a breakdown of the essential steps involved:
1. Data Preparation:
Data Collection: Gather a sufficient amount of data relevant to the task. For instance, if you're training a model for image classification, you need a large dataset of labeled images.
Data Preprocessing: Clean and preprocess the data to make it suitable for training. Common steps include:
Normalization/Standardization: Scale the data to ensure consistency, which helps in speeding up the learning process.
Augmentation (for images): Apply techniques like rotation, flipping, and scaling to artificially expand the dataset and improve model robustness.
Splitting the Data: Divide the dataset into training, validation, and testing subsets. Typically, 70-80% of the data is used for training, 10-15% for validation, and the rest for testing.
2. Model Building:
Architecture Design: Define the structure of the neural network, including the number of layers, types of layers (e.g., convolutional, recurrent), and the number of neurons in each layer.
Choosing Activation Functions: Select appropriate activation functions for the hidden layers (e.g., ReLU) and the output layer (e.g., softmax for classification tasks).
Loss Function and Optimizer Selection: Choose a loss function that matches the task (e.g., cross-entropy for classification) and an optimization algorithm (e.g., Adam) for weight updates.
3. Training:
Forward Propagation: Input data is passed through the network, and predictions are made. In each layer, the data is transformed by the neurons based on the current weights and activation functions.
Loss Calculation: The loss function calculates the error between the predicted output and the true target values.
Backpropagation: The error is propagated back through the network to adjust the weights and reduce the loss.
4. Validation:
Validation Set Usage: After each training epoch (a complete pass through the training data), the model is evaluated on the validation set. This helps in monitoring the model’s performance and detecting overfitting (where the model learns the training data too well, including noise and outliers, and fails to generalize).
Early Stopping: Training can be halted early if the model’s performance on the validation set stops improving, helping to prevent overfitting.
5. Testing:
Final Evaluation: Once training is complete, the model’s performance is tested on the testing set. This provides an unbiased evaluation of the model’s generalization ability to new, unseen data.
Backpropagation and Weights Adjustment
Explanation of Backpropagation: Backpropagation is a fundamental algorithm used for training neural networks. It is a supervised learning technique that adjusts the weights of the network based on the error rate obtained in the previous epoch (iteration).
How Backpropagation Works:
Forward Pass:
The input data is fed into the network, passing through each layer until it reaches the output layer. At each layer, the neurons apply their weights and activation functions to produce outputs.
The final output is compared to the actual target values using the loss function, which calculates the total error.
Error Calculation:
The loss function computes the difference between the predicted and actual values, resulting in a loss score that quantifies how well or poorly the model performed.
Backward Pass:
Backpropagation uses the chain rule of calculus to compute the gradient (partial derivative) of the loss function for each weight in the network.
Starting from the output layer, the algorithm moves backward through the network, layer by layer, calculating gradients for each weight.
Gradient Calculation:
The gradient indicates the direction and magnitude of change needed for each weight to minimize the loss. A positive gradient suggests that the weight should be decreased, while a negative gradient suggests an increase.
Weight Adjustment:
Learning Rate: The learning rate is a hyperparameter that determines the step size for updating weights. A small learning rate results in small, gradual updates, while a large learning rate causes faster updates but can overshoot the optimal values.
Iteration:
This process of forward propagation, error calculation, backward propagation, and weight adjustment repeats iteratively over multiple epochs until the loss converges to a minimum value or stops improving significantly.
Why Backpropagation Is Important:
Efficient Learning: Backpropagation allows neural networks to learn from errors efficiently, making it possible for models to perform complex tasks like image and speech recognition, natural language processing, and more.
Minimizing Loss: By adjusting weights in the direction that minimizes the loss, backpropagation enables the network to progressively improve its performance on the training data and generalize to new data.
Understanding these core principles of deep machine learning—how models are trained, how backpropagation works, and how weights are adjusted—provides a solid foundation for delving deeper into advanced topics and developing effective AI solutions.
Chapter 5: Tools and Frameworks for Deep Machine Learning
Popular Deep Learning Frameworks
Deep learning frameworks are essential tools that simplify the process of building, training, and deploying deep learning models. They provide pre-built functions, libraries, and interfaces that allow developers to work with neural networks more efficiently. Let’s explore some of the most popular deep-learning frameworks:
1. TensorFlow:
Introduction: Developed by Google, TensorFlow is one of the most widely used open-source frameworks for deep learning and machine learning. It provides a flexible ecosystem of tools, libraries, and community resources that enable researchers and developers to build and deploy machine learning models.
Pros:
Scalability: Capable of handling large-scale machine learning and deep learning tasks.
Versatility: Supports various neural network architectures, from simple feedforward networks to complex models like CNNs and RNNs.
Cross-Platform Compatibility: Models can be deployed on different platforms, including mobile devices, desktops, and the cloud.
Robust Community Support: Extensive documentation and a large, active community.
Cons:
Steeper Learning Curve: TensorFlow can be complex for beginners due to its extensive feature set.
Verbose Syntax: Compared to some other frameworks, TensorFlow's syntax can be more verbose, making it slightly harder to write and debug code.
2. PyTorch:
Introduction: Developed by Facebook’s AI Research lab, PyTorch is an open-source deep learning framework known for its simplicity and ease of use. It is popular for research and development due to its dynamic computation graph, which allows for more flexibility in building neural networks.
Pros:
Ease of Use: PyTorch’s syntax is intuitive and Pythonic, making it easier for beginners to learn and use.
Dynamic Computation Graph: Provides flexibility by allowing modifications to the network architecture during runtime.
Strong Research Community: Favored in academia for research and experimentation due to its flexibility and ease of debugging.
Cons:
Less Optimized for Production: While improving, PyTorch historically lagged behind TensorFlow in terms of production deployment tools.
Limited Cross-Platform Support: Deployment across different platforms can be less straightforward compared to TensorFlow.
3. Keras:
Introduction: Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, Microsoft Cognitive Toolkit (CNTK), or Theano. It simplifies building and training deep learning models through an easy-to-use interface.
Pros:
User-Friendly: Keras offers a simple and clean API, making it accessible to beginners.
Rapid Prototyping: Allows for quick and easy testing of ideas and models due to its straightforward syntax.
Integration with TensorFlow: Seamlessly integrates with TensorFlow, benefiting from TensorFlow’s powerful backend while maintaining simplicity.
Cons:
Less Customization: Higher-level abstraction may limit the ability to customize models deeply.
Performance Limitations: Not as optimized for performance as lower-level frameworks, making it less suitable for highly complex models requiring fine-tuning.
4. Other Frameworks:
MXNet: Known for its efficiency and scalability, MXNet supports multiple languages and is particularly strong in distributed training.
Caffe: Developed by the Berkeley Vision and Learning Center, Caffe is optimized for speed and is often used in image classification tasks.
Theano: One of the older frameworks, Theano was a pioneer in deep learning but is now largely superseded by newer frameworks.
Setting Up Your Deep Learning Environment
Setting up a deep learning environment requires the right combination of hardware, software, and libraries to ensure smooth training and experimentation with deep learning models.
1. Basic Requirements:
Hardware:
GPUs (Graphics Processing Units): GPUs are crucial for deep learning due to their ability to handle parallel processing tasks efficiently, which accelerates the training of large models. NVIDIA GPUs are commonly used, with CUDA support for deep learning frameworks.
RAM: Sufficient memory is needed to handle large datasets and models. A minimum of 16GB RAM is recommended, but more is preferable for extensive deep-learning tasks.
Storage: Fast storage solutions like SSDs are recommended for handling large datasets and ensuring quick read/write speeds during training.
Software and Libraries:
Operating System: Linux (e.g., Ubuntu) is the preferred OS for deep learning due to its compatibility and support from deep learning frameworks, but Windows and macOS are also supported.
Python: The primary programming language used in deep learning. It is essential to have Python installed, along with package management tools like pip or conda.
2. Step-by-Step Guide to Setting Up a Deep Learning Environment:
Step 1: Install Python and a Package Manager
Download and install the latest version of Python from the official Python website or Anaconda, which includes a package manager and many pre-installed libraries useful for data science and deep learning.
Step 2: Set Up a Virtual Environment
Use virtual environments to create isolated spaces for your projects, avoiding conflicts between different project dependencies. You can set up a virtual environment using venv (built-in Python module) or Conda.
Step 3: Install Deep Learning Frameworks
Choose your preferred framework (e.g., TensorFlow, PyTorch, Keras) and install it using pip or conda.
Similarly, install PyTorch by following the official installation guide on the PyTorch website, which provides platform-specific installation commands.
Step 4: Install Additional Libraries
Install essential libraries for data manipulation and visualization, such as NumPy, pandas, matplotlib, and scikit-learn.
Step 5: Verify GPU Setup (Optional)
For GPU support, ensure that your system has the necessary drivers and CUDA installed.
Step 6: Test the Setup
Create a simple script to load a dataset, build a basic neural network, and train it to ensure everything is working correctly. This will help confirm that the environment is correctly set up and ready for deep learning tasks.
Setting up a well-configured deep-learning environment is a crucial step for any beginner. It provides the foundation needed to explore and experiment with deep learning concepts effectively, leveraging the powerful tools and frameworks available today.
Chapter 6: Practical Applications of Deep Machine Learning
Deep machine learning has revolutionized many industries by providing innovative solutions to complex problems. Its ability to process large amounts of data and learn intricate patterns has made it invaluable in various fields. This chapter explores some of the most common applications of deep machine learning and presents case studies that illustrate its real-world impact.
Common Applications
1. Image Recognition:
Overview: Image recognition involves identifying and classifying objects, people, and other elements within images. Deep learning models, especially Convolutional Neural Networks (CNNs), are highly effective in this domain.
Applications:
Medical Imaging: Detecting diseases such as cancer in medical scans (e.g., MRIs, X-rays).
Facial Recognition: Used in security systems and social media platforms for identifying individuals.
Object Detection: Applications in retail (e.g., inventory management), agriculture (e.g., crop monitoring), and manufacturing (e.g., defect detection).
2. Speech Recognition:
Overview: Speech recognition is the ability of a machine to identify spoken words and convert them into text. Recurrent Neural Networks (RNNs), particularly Long Short-Term Memory (LSTM) networks, are commonly used for this purpose.
Applications:
Virtual Assistants: Siri, Google Assistant, and Alexa rely on deep learning for understanding and responding to voice commands.
Transcription Services: Automatic transcription of audio into text for business meetings, lectures, and more.
Accessibility Tools: Assisting individuals with disabilities by converting speech to text or commands.
3. Natural Language Processing (NLP):
Overview:NLP enables machines to understand, interpret, and generate human language. Techniques like word embeddings, Transformers, and attention mechanisms are employed in NLP tasks.
Applications:
Chatbots and Customer Service: Providing automated, intelligent responses to customer queries.
Sentiment Analysis: Analyzing social media posts, reviews, or any text data to gauge public sentiment.
Language Translation: Tools like Google Translate use deep learning to provide real-time language translation.
4. Autonomous Vehicles:
Overview: Deep learning is a critical component in the development of self-driving cars, allowing vehicles to perceive their environment and make driving decisions.
Applications:
Perception: Detecting obstacles, traffic signs, lanes, and pedestrians using CNNs and sensor fusion techniques.
Decision Making: Determining the optimal path, speed, and actions using deep reinforcement learning algorithms.
Control Systems: Ensuring the vehicle maintains its lane, follows traffic rules, and adapts to dynamic road conditions.
5. Fraud Detection:
Overview:Deep machine learning modelsanalyze transaction data to identify patterns indicative of fraudulent behavior. They can detect anomalies in financial transactions, credit card activities, and more.
Applications:
Financial Institutions: Real-time monitoring of transactions to flag potential fraud.
E-commerce: Detecting suspicious activities such as account takeovers or false claims.
6. Healthcare and Drug Discovery:
Overview: Deep machine learning assists in predicting patient outcomes, personalizing treatment plans, and accelerating drug discovery.
Applications:
Predictive Diagnostics: Identifying high-risk patients and predicting disease progression.
Drug Development: Analyzing chemical structures to discover new drugs and predict their efficacy.
Case Studies
Case Study 1: Image Recognition in Healthcare
Context: A major healthcare provider implemented deep learning models to improve the accuracy of cancer detection in radiology images.
Approach: The model, a CNN trained on thousands of labeled medical images, could detect abnormalities with high precision.
Results: The deployment of this deep learning model led to a significant reduction in diagnostic errors and improved patient outcomes by enabling earlier and more accurate detection of cancer.
Case Study 2: Speech Recognition in Customer Service
Context: A global telecommunications company deployed a speech recognition system to streamline their customer support process.
Approach: By integrating deep learning-based speech-to-text models, they automated call routing and responses for frequently asked questions.
Results: The company saw a 30% reduction in call handling times and increased customer satisfaction due to faster service and resolution times.
Case Study 3: NLP for Sentiment Analysis in Marketing
Context: A leading retail brand used deep learning for sentiment analysis to better understand customer feedback across social media platforms.
Approach: Using a combination of LSTM networks and Transformers, the model analyzed large volumes of customer reviews and social media posts to identify trends and sentiments.
Results: The insights gained allowed the company to tailor its marketing strategies, resulting in a 20% increase in customer engagement and sales.
Case Study 4: Autonomous Vehicles: Enhancing Safety and Efficiency
Context: A tech company focused on autonomous vehicles used deep learning to improve the safety features of their self-driving cars.
Approach: The system integrated CNNs for object detection and deep reinforcement learning for decision-making under various driving conditions.
Results: The vehicles achieved a higher level of safety and efficiency, reducing accident rates and improving navigation accuracy in complex urban environments.
Case Study 5: Fraud Detection in Banking
Context: A multinational bank implemented deep learning models to detect and prevent fraudulent transactions.
Approach: The model used deep neural networks to analyze transaction patterns and identify anomalies that could indicate fraud.
Results: The system successfully reduced fraudulent activities by 40%, saving the bank millions in potential losses and enhancing trust among customers.
These practical applications and case studies highlight the transformative power of deep machine learning across various industries. By understanding the real-world impact and potential of deep learning, you can better appreciate its significance and explore how to apply these concepts in your own projects and career.
Chapter 7: Challenges and Limitations of Deep Machine Learning
While deep machine learning has brought about groundbreaking advancements, it is not without its challenges and limitations. Understanding these barriers is crucial for anyone looking to work with or develop deep learning models. This chapter explores common challenges, ethical considerations, and the future trends that are shaping the evolution of deep machine learning.
Common Challenges
1. Overfitting:
Definition: Overfitting occurs when a model learns the training data too well, including noise and outliers, resulting in poor generalization to new, unseen data.
Causes:
Excessively complex models with too many parameters.
Insufficient training data or data that is not representative of real-world scenarios.
Mitigation Strategies:
Regularization: Techniques such as L1 and L2 regularization help to penalize overly complex models.
Dropout: Randomly disabling neurons during training to prevent the network from becoming too reliant on specific paths.
Cross-Validation: Using cross-validation techniques to validate the model's performance on unseen data subsets.
2. High Computational Costs:
Overview: Deep learning models, especially those with many layers and large datasets, require significant computational resources. Training these models can be time-consuming and expensive.
Challenges:
Requirement for high-performance hardware, such as GPUs or TPUs.
Long training times, particularly for large-scale models.
Solutions:
Model Optimization: Techniques like model pruning, quantization, and knowledge distillation can reduce the size and complexity of models.
Cloud Computing: Leveraging cloud-based solutions to access scalable resources without the need for substantial upfront hardware investments.
3. Data Dependency:
Overview: Deep learning models are heavily dependent on large volumes of high-quality data. The performance of a model is directly linked to the quality, diversity, and quantity of the data it is trained on.
Challenges:
Data scarcity in specialized or niche applications.
High costs and time associated with data collection, labeling, and preprocessing.
Mitigation Strategies:
Data Augmentation: Techniques like rotation, scaling, and flipping images to artificially increase the training dataset.
Synthetic Data: Generating artificial data using simulations or Generative Adversarial Networks (GANs) when real data is limited.
Ethical Considerations
1. Bias in Models:
Overview: Deep learning models can inherit biases present in their training data, leading to unfair or discriminatory outcomes.
Examples:
Biased facial recognition systems that perform poorly on certain demographic groups.
Predictive models in hiring that favor candidates from specific backgrounds.
Mitigation Strategies:
Diverse Training Data: Ensuring that training datasets are representative of all relevant groups.
Bias Detection and Correction: Implementing fairness metrics and techniques to identify and reduce bias in models.
2. Data Privacy Concerns:
Overview: Deep learning models often require vast amounts of personal data, raising concerns about data privacy and security.
Challenges:
Risks of data breaches or misuse of personal information.
Compliance with regulations like GDPR and CCPA.
Solutions:
Data Anonymization: Techniques to ensure that personal identifiers are removed from data.
Federated Learning: A privacy-preserving approach where models are trained across multiple devices without centralizing the data.
Future Trends
1. Improved Efficiency and Accessibility:
Overview: Future advancements aim to make deep learning models more efficient and accessible, even for those with limited resources.
Trends:
Development of smaller, more efficient models that can run on edge devices.
Democratization of AI tools, making them more accessible through user-friendly platforms and low-code/no-code solutions.
2. Integration of Multimodal Learning:
Overview: Multimodal learning involves integrating multiple types of data (e.g., text, images, audio) to improve model performance.
Potential: Enhancing applications in areas such as autonomous vehicles (integrating visual, auditory, and sensor data) and personalized healthcare.
3. Explainability and Interpretability:
Overview: As deep learning models become more complex, there is a growing need for tools that make their decisions more understandable to humans.
Trends:
Development of techniques for model explainability, such as LIME (Local Interpretable Model-Agnostic Explanations) and SHAP (SHapley Additive exPlanations).
Increasing demand for models that can justify their predictions in critical fields like finance and healthcare.
4. Ethical AI and Responsible AI:
Overview: The AI community is increasingly focused on developing frameworks and guidelines for ethical AI use, addressing biases, and ensuring fairness.
Future Directions:
Establishing standardized protocols for ethical AI development.
Increasing collaboration between AI developers, ethicists, and policymakers to create regulations that balance innovation with societal impacts.
5. Quantum Machine Learning:
Overview: Quantum computing has the potential to revolutionize machine learning by providing immense computational power for complex problems.
Potential Impact:
Accelerating training times for deep learning models.
Enabling solutions for problems currently infeasible for classical computers.
By understanding these challenges, ethical considerations, and future trends, you can navigate the evolving landscape of deep machine learning with a more informed perspective, ready to leverage its power while being mindful of its limitations and responsibilities.
Conclusion
As we wrap up this beginner’s guide to deep machine learning, it's essential to recap the key points and provide guidance on how to continue your learning journey. Deep machine learning is a vast and ever-evolving field, with opportunities for innovation, exploration, and career growth. By understanding its basics, you have taken the first step toward becoming proficient in this transformative technology.
Recap of Key Points
Understanding Deep Machine Learning:
Deep learning is a subset of machine learning that uses neural networks with multiple layers (deep architectures) to model complex patterns in data.
It mimics the human brain’s neural structure, enabling advanced capabilities such as image recognition, natural language processing, and autonomous decision-making.
Fundamentals of Neural Networks:
Neural networks consist of layers (input, hidden, and output), neurons, and activation functions that work together to process information.
Key components like activation functions, optimization, and loss functions play crucial roles in training effective models.
Training and Architectures:
Training deep learning models involves data preparation, model building, backpropagation, and weight adjustment to minimize errors.
Various architectures such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Generative Adversarial Networks (GANs) serve specific use cases.
Challenges and Considerations:
Deep learning faces challenges such as overfitting, high computational costs, and data dependency.
Ethical considerations, including bias in models and data privacy concerns, are critical to responsible AI development.
Next Steps for Beginners
To continue your journey into deep machine learning, consider the following steps and resources:
Start with Hands-On Practice:
Experiment with Code: Utilize open-source frameworks like TensorFlow, PyTorch, and Keras. Try building simple models, such as digit recognizers with the MNIST dataset or image classifiers using CIFAR-10.
Work on Projects: Apply deep learning to personal or community projects. Experimenting with real data will deepen your understanding and problem-solving skills.
Join Online Communities:
Engage with online forums and communities such as Stack Overflow, GitHub, Reddit’s r/MachineLearning, and AI groups on LinkedIn. Sharing knowledge and seeking help from peers can significantly accelerate your learning.
Stay Updated:
Deep learning is a rapidly advancing field. Follow blogs, subscribe to newsletters like Towards Data Science or DeepAI, and keep up with recent papers on platforms like arXiv.
Additional Resources
Suggested Reading and Courses
Books:
"Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: A comprehensive guide to deep learning, covering fundamental theories and practical implementations.
"Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow" by Aurélien Géron: A practical guide that combines theory with hands-on coding exercises.
Online Resources:
Fast.ai’s Practical Deep Learning for Coders: A free course that takes a top-down approach, starting with the practical application before delving into the theory.
Kaggle: Engage in competitions, explore datasets, and learn through practical problem-solving with the data science and machine learning community.
Unlock the Power of Data with Infiniticube’s Machine Learning Solutions
Transform your business with AI-driven insights and automation. Our tailored machine-learning services help you predict trends, optimize operations, and make smarter decisions.
Digital Marketing Specialist at Infiniticube, a leading app development and digital marketing agency in India. I specialize in B2B lead generation, AI-driven marketing solutions, and blockchain technology. Follow along for actionable insights on software trends and digital growth strategies for 2025 and beyond.
Our newsletter is finely tuned to your interests, offering insights into AI-powered solutions, blockchain advancements, and more. Subscribe now to stay informed and at the forefront of industry developments.











 June 27, 2025
June 27, 2025
 Balbir Kumar Singh
Balbir Kumar Singh
 0
0


Leave a Reply