Artificial Intelligence (AI) involves creating systems that perform tasks requiring human intelligence, such as decision-making and problem-solving. Its purpose is to enhance human capabilities, automating complex tasks using vast data and algorithms. AI is divided into narrow AI, which handles specific tasks, and general AI, which aspires to replicate human-like intelligence.
AI is transforming industries like healthcare, finance, retail, and manufacturing, improving efficiency and customer experience. Machine learning (ML), a subset of AI, enables systems to learn from data autonomously, identifying patterns and enhancing performance without explicit programming. ML is crucial for driving advancements in AI applications, including recommendation systems, image recognition, fraud detection, and natural language processing.
Machine learning (ML) is a branch of artificial intelligence (AI) that allows systems to automatically learn from data and improve performance over time without explicit programming. While AI focuses on enabling machines to simulate intelligent behavior, machine learning hones in on the specific ability of systems to learn from experience, which makes them progressively better at tasks such as predictions, classifications, or decision-making.
In traditional programming, specific rules and instructions must be written for a machine to perform a task. However, in machine learning, algorithms analyze data to recognize patterns and make decisions with minimal human intervention. This data-driven learning process makes machine learning an essential component of modern AI systems.
Key Concepts
Data: Data is the foundation of machine learning. Models learn from datasets, which consist of inputs (features) and expected outputs (labels). Quality and quantity of data are crucial for producing accurate predictions.
Algorithms: Machine learning algorithms are the mathematical frameworks that guide the learning process. They are designed to identify patterns in the data and develop models based on those patterns. Different algorithms are suited to different types of tasks.
Models: A model in machine learning is the final product of training an algorithm on data. The model can then be used to make predictions or decisions based on new, unseen data. For example, a spam filter is a model trained to classify emails as spam or not based on past data.
How Machine Learning Works
The machine learning process begins with training data—historical or labeled data that serves as the learning material for the system. This training data is fed into a machine learning algorithm, which processes the data and identifies relationships between inputs (features) and the desired outputs (targets or labels). Through this process, the algorithm builds a model that can be used to make predictions about new, unseen data.
Steps in the learning process:
Data Collection: Gathering relevant data for training the model.
Data Preprocessing: Cleaning and preparing data, handling missing values, and ensuring the data is in a suitable format.
Model Training: Feeding the algorithm with training data and letting it learn the relationships between inputs and outputs.
Model Evaluation: Assessing the model's performance using test data to determine accuracy and reliability.
Model Tuning: Adjusting parameters or retraining the model to improve performance and avoid issues like overfitting (when a model performs well on training data but poorly on new data).
The Role of Patterns and Predictions in ML
Machine learning systems rely on patterns in data to make accurate predictions. For example, an ML model trained on customer data may recognize patterns in purchasing behavior and use those patterns to predict future purchases. These patterns allow the model to generalize and apply the learned relationships to new, unseen data.
Example
Consider an ML model designed to identify objects in images (e.g., distinguishing between cats and dogs).
The process involves:
The model is trained on a labeled dataset of images containing both cats and dogs.
The algorithm learns the features that distinguish a cat from a dog, such as the shape of ears, tail, or overall body structure.
Once the model is trained, it can analyze new images, extract key features, and predict whether the image contains a cat or a dog based on the patterns learned from the training data.
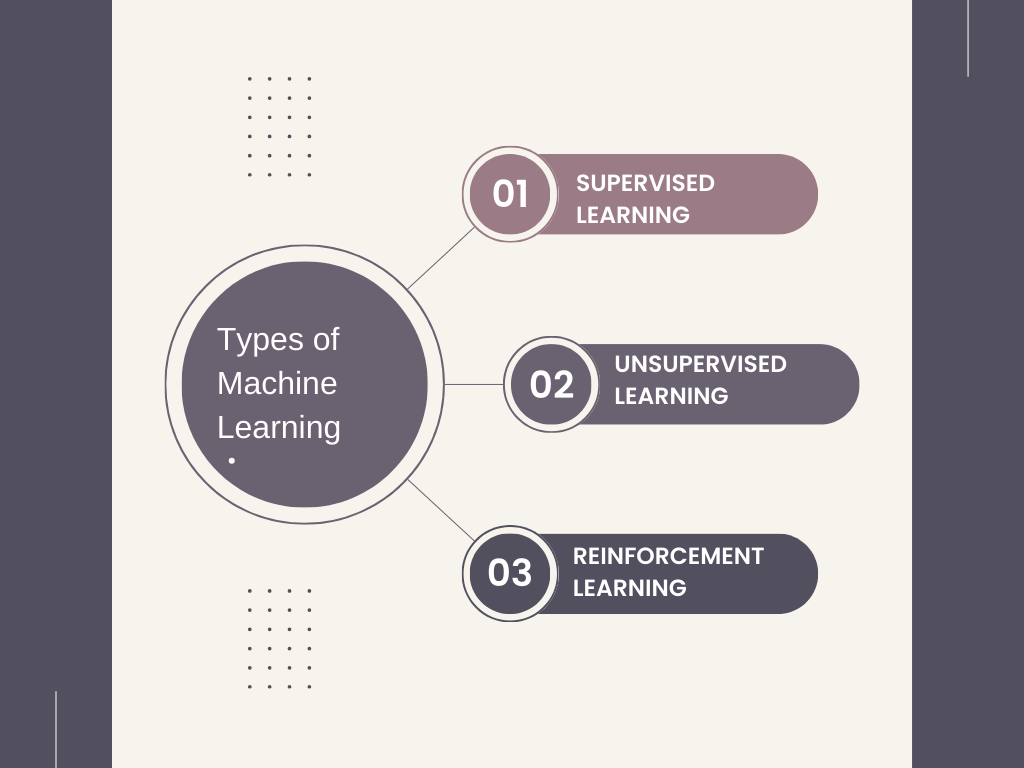
Types of Machine Learning
Supervised Learning
Supervised learning is the most common type of machine learning. In this approach, the algorithm is provided with both input data (features) and corresponding output labels (targets). The goal is for the model to learn the mapping from input to output to predict the correct label when given new data.
Key Features:
The presence of labeled data for training.
A clear target or goal (e.g., classifying emails as spam or not).
The model improves as it processes more labeled examples.
Examples:
Spam Detection: A supervised learning model is trained on a dataset of emails, labeled as either "spam" or "not spam." By learning patterns in the text, the model can predict whether a new email is spam.
Image Classification: A model can be trained on labeled images of objects (e.g., cars, animals, furniture) and used to classify new images based on learned patterns.
Unsupervised Learning
In unsupervised learning, the model is trained on data that does not have labeled outputs. Instead of learning from labeled data, the algorithm explores the structure of the data, identifying patterns, groupings, or relationships on its own. The model’s task is to uncover hidden patterns or relationships within the dataset.
Key Features:
No labeled data is provided to the model.
The focus is on identifying patterns, structures, or clusters in the data.
The model outputs groupings or associations rather than specific predictions.
Examples:
Customer Segmentation: Unsupervised learning can group customers into segments based on purchasing behavior, demographics, or preferences. These segments can then be used for targeted marketing.
Anomaly Detection: Algorithms can be used to detect unusual or anomalous data points in systems, such as fraudulent transactions or network intrusions, by identifying patterns that deviate from the norm.
Reinforcement Learning
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties based on its actions, and it uses this feedback to improve its future decision-making. Reinforcement learning focuses on trial-and-error learning, where the agent's goal is to maximize cumulative rewards over time.
Key Features:
Learning through interactions with the environment.
Receiving rewards or penalties to guide learning.
The agent's goal is to maximize long-term rewards.
Example:
In self-driving cars, reinforcement learning can be used to teach the vehicle to make decisions, such as when to accelerate, brake, or turn. The car is an agent in its environment (the road), and its actions (e.g., driving straight, turning left) lead to either positive or negative outcomes (rewards for avoiding obstacles, penalties for collisions). By continuously interacting with its environment, the car learns to make optimal decisions that lead to safer and more efficient driving.
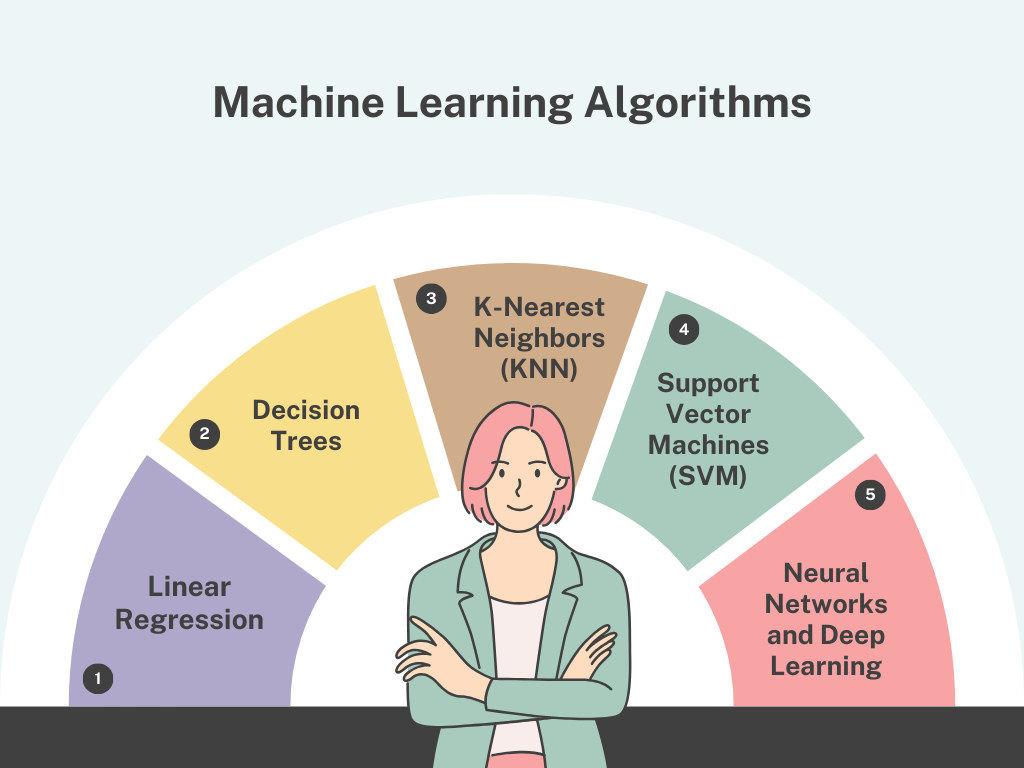
Linear regression is one of the simplest and most commonly used algorithms for predictive modeling, especially in scenarios where the goal is to predict a continuous value. The idea behind linear regression is to find the linear relationship between an independent variable (input) and a dependent variable (output). In its simplest form, linear regression fits a line to the data that minimizes the error between the predicted values and the actual values.
Formula: y=mx+b
Use Cases: Predicting house prices, forecasting sales, and analyzing trends over time.
Example: A model that predicts a person's weight based on their height using a line of best fit.
Decision Trees
Decision treesare intuitive models that split data into subsets based on the value of input features, creating a tree-like structure of decisions. Each internal node represents a decision based on a feature, while each leaf node represents the output. The simplicity of decision trees makes them easy to understand and interpret, though they can be prone to overfitting.
How It Works: The tree algorithm selects the best feature to split the data at each node by calculating measures such as Gini impurity or entropy.
Use Cases: Classifying patients based on symptoms, deciding whether a loan applicant is likely to repay, or identifying whether an email is spam.
Example: A tree model that classifies whether a passenger survived on the Titanic based on their age, fare, and class.
K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) is a non-parametric algorithm used for both classification and regression tasks. It works by finding the 'k' nearest data points (neighbors) to a given data point and assigning the most common label (classification) or averaging the nearest values (regression). KNN is simple to implement and effective for smaller datasets.
How It Works: The algorithm calculates the distance (usually Euclidean distance) between the data point and all other points and then selects the nearest neighbors.
Use Cases: Recognizing handwritten digits, detecting anomalies in network traffic, and recommendation systems.
Example: A model that classifies an animal as a dog or a cat based on the features (e.g., weight, size) of the nearest animals in the dataset.
Support Vector Machines (SVM)
Support Vector Machines (SVM) are powerful algorithms for classification tasks. SVM works by finding a hyperplane that best separates the data into different classes. It aims to maximize the margin between the closest data points (support vectors) from each class. SVMs are particularly effective in high-dimensional spaces and work well for both linear and non-linear classification tasks using kernel functions.
How It Works: The algorithm identifies a hyperplane that maximally separates the data, using support vectors to define the boundary.
Use Cases: Text classification (e.g., spam vs. not spam), image recognition, and bioinformatics.
Example: A model that separates emails into categories of spam or non-spam based on words and frequency.
Neural Networks and Deep Learning: Advanced Algorithms for Complex Tasks
Neural networksare a series of algorithms that attempt to mimic the human brain's function in learning from data. Neural networks consist of layers of nodes (neurons) that pass information through weighted connections. Deep learning, a subset of machine learning, uses neural networks with many layers (deep neural networks) to solve complex problems like image recognition, speech processing, and language translation.
How It Works: Information passes through layers of neurons, each adjusting weights to minimize error between predicted and actual outputs. Backpropagation is used to adjust weights iteratively.
Use Cases: Image recognition, natural language processing (NLP), autonomous vehicles, and medical diagnoses.
Example: A deep learning model used for facial recognition in social media platforms.
How Algorithms Learn
Training an algorithm involves feeding it data and letting it learn from that data by minimizing errors and adjusting internal parameters. The algorithm makes predictions based on patterns it identifies, and the difference between predicted and actual results is used to adjust the model.
Training Process: Algorithms learn through iterative processes, refining their predictions with each cycle. During training, data is split into training and testing sets, and the algorithm uses feedback to reduce prediction errors.
Error Reduction: Metrics, like mean squared error (for regression) or accuracy (for classification), are used to assess and reduce the difference between predictions and actual outcomes.
Model Optimization: Techniques like cross-validation and hyperparameter tuning (adjusting factors like learning rate, number of layers, etc.) are applied to improve model performance.
Concepts like Overfitting, Underfitting, and How to Balance Models
Overfitting: Occurs when a model learns the noise in the training data too well, leading to poor generalization of new data. The model becomes overly complex and performs well on training data but fails on test data.
Underfitting: Happens when the model is too simple and fails to capture the underlying patterns in the data. This leads to poor performance on both training and test sets.
Balancing Models: Strategies like cross-validation, regularization, and pruning can help find the right balance between complexity and generalization, ensuring that the model performs well on unseen data.
Chapter 3: The Machine Learning Process
Steps in Building a Machine Learning Model
Step 1: Data Collection:
The first and most crucial step in machine learning is collecting the data that will be used to train the model. Data is the lifeblood of machine learning, and both its quality and quantity are essential for creating effective models. Poor or insufficient data can lead to inaccurate predictions, while high-quality, relevant data can lead to powerful and reliable models.
Quality: Clean, accurate, and relevant data that is free from bias and errors is crucial.
Quantity: A larger volume of diverse data can help the model generalize better and make more accurate predictions.
Step 2: Data Preprocessing:
Once data is collected, it must be preprocessed to ensure that it is ready for model training. This step involves cleaning, transforming, and organizing the data.
Cleaning: Handling missing values, removing duplicates, and correcting errors.
Transforming: Converting data into the appropriate format, such as scaling numerical data or encoding categorical data.
Organizing: Splitting data into training, validation, and testing sets to ensure the model can generalize well.
Step 3: Choosing the Right Algorithm
Selecting the right algorithm depends on several factors, including the type of problem (classification vs. regression), the nature of the data (structured vs. unstructured), and the size and complexity of the dataset. Other considerations include:
Accuracy needs: Some algorithms offer higher accuracy but require more data or computing power.
Interpretability: Simple models like decision trees are easier to interpret, while more complex models like neural networks offer better performance but are harder to explain.
Training time: Algorithms vary in how long they take to train, so resource availability may influence the choice.
Step 4: Training the Model
Once the algorithm is chosen, the next step is to train the model. This involves feeding the training data into the algorithm, which learns from the data by adjusting internal parameters to minimize error. The training process includes:
Feeding data: Providing input features and labels for the algorithm to learn from.
Adjusting parameters: As the model makes predictions, it adjusts its internal parameters to reduce the error.
Step 5: Testing and Evaluation
After training, the model is evaluated using a testing dataset (which was not used during training). Key metrics for evaluation include:
Accuracy: Measures how often the model correctly predicts the target.
Precision and Recall: Used in classification tasks to measure how well the model identifies positive cases and avoids false positives.
Other Metrics: Metrics like the F1-score, confusion matrix, and area under the curve (AUC) can be used to assess performance depending on the problem.
Step 6: Model Optimization
Optimizing a machine learning modelinvolves tuning hyperparameters (such as learning rate, regularization strength, or depth of decision trees) to improve performance. Techniques such as grid search and random search are commonly used for this purpose. Cross-validation is also a key part of the optimization process, ensuring the model generalizes well to new data.
Example of a Simple Machine Learning Workflow
Building a Spam Email Filter from Scratch Using a Basic Algorithm
To illustrate the machine learning process, consider building a spam email filter. Here's how the workflow might look:
Data Collection: Gather a dataset of emails labeled as "spam" or "not spam."
Data Preprocessing: Clean the email data by removing special characters, stopwords, and irrelevant content. Transform text data into numerical features using techniques like TF-IDF.
Algorithm Selection: Choose a basic algorithm like Naive Bayes, which works well for text classification problems.
Model Training: Train the model using labeled emails, allowing it to learn the patterns that distinguish spam from non-spam.
Testing and Evaluation: Evaluate the model’s accuracy on a separate test set of emails to see how well it classifies new messages.
Model Optimization: Tune parameters like smoothing or feature selection to improve accuracy and reduce false positives/negatives.
This workflow demonstrates the key steps involved in building a machine-learning model from data collection to optimization.
Chapter 4: Tools and Technologies for Machine Learning
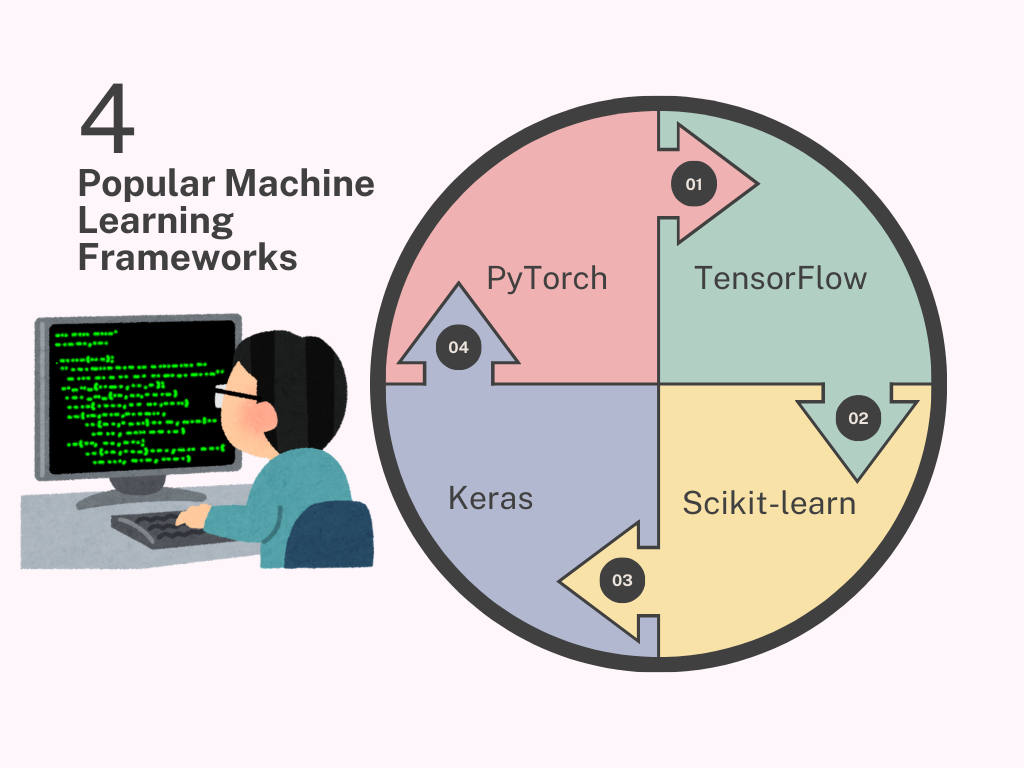
Popular Machine Learning Frameworks and Libraries
TensorFlow
TensorFlowis an open-source machine learning framework developed by Google, designed for both beginners and advanced users. It supports a wide range of machine learning tasks, including neural networks, deep learning, and other advanced models. TensorFlow offers flexibility with both high-level and low-level APIs, enabling users to build models from scratch or use pre-built components.
Key Features: Automatic differentiation, flexible architecture, scalability, and support for both CPUs and GPUs.
Use Cases: Image classification, natural language processing (NLP), time-series forecasting, and reinforcement learning.
Example: Using TensorFlow to build a neural network that recognizes handwritten digits from the MNIST dataset.
Scikit-learn
Scikit-learn is one of the most popular machine-learning libraries in Python, especially for beginners. It provides simple and efficient tools for data analysis and modeling, covering tasks like classification, regression, clustering, and dimensionality reduction. Scikit-learn is built on top of other Python libraries like NumPy and SciPy, and it's designed to be accessible for both newcomers and experienced developers.
Key Features: Pre-built algorithms, data preprocessing tools, and easy model evaluation methods.
Use Cases: Predicting housing prices, classifying customer segments, and clustering data.
Example: Building a simple linear regression model to predict house prices based on features like square footage and number of bedrooms.
Keras
Kerasis a high-level neural networks API that runs on top of TensorFlow, making deep learning more accessible. It simplifies the creation and training of complex deep learning models with minimal code. Keras is ideal for rapid prototyping and is often used in academic research and industry for tasks like image classification and natural language processing.
Key Features: User-friendly, modular, and allows for easy experimentation.
Use Cases: Building deep learning models for image recognition, sentiment analysis, and time-series forecasting.
Example: Using Keras to develop a convolutional neural network (CNN) for classifying images of animals.
PyTorch
PyTorch is another open-source machine learning library, developed by Facebook’s AI Research lab. It’s known for its flexibility, dynamic computation graphs, and ease of debugging, which make it highly popular in academic research and industrial applications. PyTorch excels in creating deep learning models and has a strong ecosystem for reinforcement learning and other advanced AI tasks.
Key Features: Dynamic computation graphs, seamless integration with Python, and excellent support for GPUs.
Use Cases: NLP, computer vision, and reinforcement learning.
Example: Using PyTorch to create a generative adversarial network (GAN) for generating realistic images.
Programming Languages for Machine Learning
Overview of Popular Languages Used for ML Development
Python
Python is the most widely used language in the machine learning community due to its simplicity and the vast array of libraries and frameworks available (such as TensorFlow, Keras, and Scikit-learn). Its readability and ease of use make it an excellent choice for both beginners and professionals.
Strengths: Extensive ML libraries, supportive community, and easy-to-read syntax.
Use Cases: Web scraping, data preprocessing, building machine learning models, and deep learning.
R
R is another popular language used for statistical computing and machine learning. It is known for its powerful data visualization tools and is commonly used by data scientists and statisticians.
Strengths: Excellent for data manipulation, visualization, and statistical modeling.
Use Cases: Statistical analysis, predictive modeling, and data visualization.
Chapter 5: Real-World Applications of Machine Learning
Healthcare
Machine learning revolutionizes healthcare by providing predictive models, diagnosing diseases, and creating personalized treatment plans based on patient data. The use of ML can lead to more accurate diagnoses and better patient outcomes.
Examples:
Predicting Patient Outcomes: Machine learning algorithms analyze patient data, such as lab results and medical history, to predict the likelihood of future health events (e.g., heart attacks, hospital readmissions).
Diagnosing Diseases: ML models can assist in diagnosing diseases by analyzing medical images, such as X-rays or MRIs, with greater accuracy than traditional methods.
Personalized Treatment Plans: By analyzing genetic data and treatment responses, machine learning helps doctors create personalized treatment plans tailored to individual patients.
Finance
The finance industry has embraced machine learning for various applications, including fraud detection, stock market predictions, and personalized banking services.
Examples:
Fraud Detection: Machine learning models are used to identify unusual patterns in transaction data that might indicate fraudulent activity.
Stock Market Predictions: ML algorithms analyze vast amounts of historical stock data and market trends to forecast stock prices and optimize investment portfolios.
Personalized Banking: Banks use machine learning to personalize offers, recommend financial products, and provide tailored advice based on a customer’s spending habits and financial goals.
E-commerce
E-commerce platforms leverage machine learning to enhance user experiences, improve sales, and optimize operations. From personalized recommendations to dynamic pricing, ML plays a key role in driving success.
Examples:
Product Recommendations: ML algorithms analyze customer behavior and preferences to provide personalized product recommendations, increasing sales and customer satisfaction.
Dynamic Pricing: Machine learning models can adjust prices in real time based on demand, inventory, competitor pricing, and other factors, optimizing revenue.
Customer Behavior Analysis: ML analyzes patterns in customer behavior to forecast trends, optimize marketing strategies, and improve customer retention.
Autonomous Vehicles
Machine learning is the backbone of self-driving cars, enabling them to make real-time decisions by processing data from sensors, cameras, and other inputs. It allows autonomous vehicles to navigate roads, avoid obstacles, and make predictions about the behavior of other drivers and pedestrians.
Examples:
Real-Time Decision Making: ML algorithms process vast amounts of data from cameras, LIDAR, and radar systems to make split-second decisions, such as when to brake or accelerate.
Object Detection: Machine learning models enable cars to recognize objects in their surroundings, including other vehicles, pedestrians, and traffic signs.
Path Planning: ML helps autonomous vehicles calculate optimal routes and avoid hazards or traffic, enhancing efficiency and safety.
Bonus: Resources for Further Learning
Top Machine Learning Courses for Beginners:
Coursera: Courses like Andrew Ng's Machine Learning provide a strong foundation. Other platforms such as edX and Udemy offer a range of ML courses suitable for all levels.
Udacity: They offer a Machine Learning Nanodegree with real-world projects and mentorship (Udacity).
Books and Documentation:
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurélien Géron.
Documentation on Scikit-learn, TensorFlow, and PyTorch.
Communities and Forums:
Kaggle: A great platform for datasets, competitions, and community collaboration in ML.
Stack Overflow: Popular for troubleshooting and interacting with experts in AI and ML( freeCodeCamp).
Unlock The Power of Machine Learning for Your Business!
Our expert team provides end-to-end ML services, from data preprocessing to advanced algorithm development, tailored to your unique needs. Whether you're looking to implement predictive models, automate tasks, or leverage AI for real-time decision-making, we've got you covered.
He is working with infiniticube as a Digital Marketing Specialist. He has over 3 years of experience in Digital Marketing. He worked on multiple challenging assignments.
Our newsletter is finely tuned to your interests, offering insights into AI-powered solutions, blockchain advancements, and more. Subscribe now to stay informed and at the forefront of industry developments.











 June 27, 2025
June 27, 2025
 Balbir Kumar Singh
Balbir Kumar Singh
 0
0


Leave a Reply