Why Data Scientists And ML Developers Are Impressed With AWS SageMaker?
Do you know that data scientists must create, train, and use a variety of models as they work? In most environments, they have a lot of difficulties modifying the necessary processes and resources.
If you are a Data Scientist or ML Developer, you might understand the hardship. So, for this specific issue, AWS has created AWS SageMaker, a simple but effective service. On the basis of this, this article will go on what makes SageMaker a different Product that is more reliable and secure as well.
And you might even be aware that there aren't any integrated tools for the entire machine learning workflow, traditional ML development is a complex, expensive, and iterative process. It takes time and is prone to error to piece together tools and workflows.
Thanks to Amazon SageMaker, a fully managed service, any developer or data scientist can quickly create, train, and deploy machine learning (ML) models. SageMaker overcomes this difficulty by combining all machine learning components into a single toolset, allowing models to be produced more quickly and at a lower cost. It eliminates the time-consuming tasks from each stage of the machine learning process to make it easier to produce high-quality models.
And if you are someone who is interested in scalable Model Deployment via Amazon SageMaker, get in touch with Infiniticube or schedule a call with a Sagemaker expert by clicking here. Our Expert will be happy to assist you in order to solve your issues and provide the best services possible.
And if not and you haven’t read our previous article How AWS SageMaker Ensures Reliable Impact On Machine Learning Developers And Data Scientists, then I recommend you to read that article after reading this. It will help you to clear your concepts more precisely. But still, I’m giving you a short tour of the introduction.
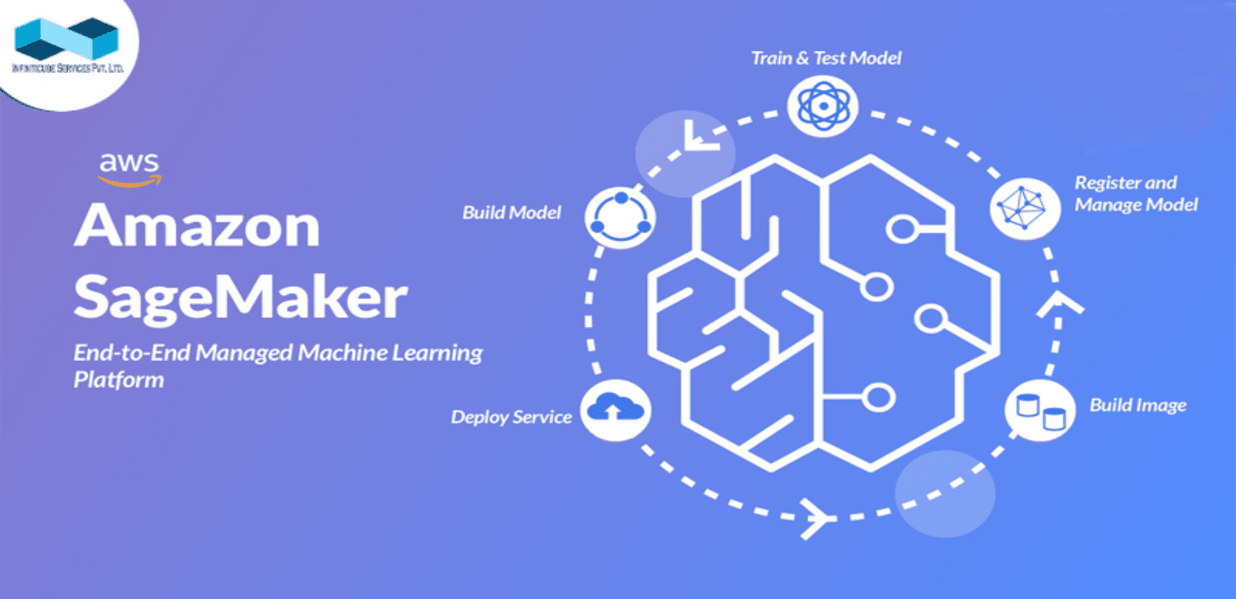
Amazon SageMaker in Short Brief
You can create, deploy, and monitor applications on a number of services and on-demand cloud platforms provided by Amazon. Numerous efficient tools and services, including AWS SageMaker, are available within the cloud platform and are extremely handy and helpful to both beginning and seasoned data scientists.
Advantages of Using AWS SageMaker
- Productivity: It is increased because Sagemaker allows the user to deploy and manage tasks efficiently, which reduces the likelihood of work delays.
- Scalability: Its high scalability can enable users to scale up or down in response to needs. Additionally, it encourages quicker model training.
- Storage: This requirement can rise quickly when working with ML models. However, it provides you with access to the necessary storage to assist with this problem. You can now keep all the ML models and components in one place.
- Cost: Using SageMaker, you can build and deploy ML models for up to 70% less money.
- Saving time: It makes it simpler to maintain and create Amazon Elastic Compute Cloud (EC2) instances quickly.
Machine learning possibilities with AWS SageMaker
Machine learning (ML) is made simple with SageMaker. Let's discuss how SageMaker can be used to build, test, tune, and deploy an entire model as it relates to the implementation of ML or MLOps.
How To Build?
For builds and training purposes, Amazon SageMaker has prepared a compilation of the top 10 frequently used ML algorithms for your dashboard. Additionally, you have a specific server size and notebook instance choice. You can also decide to use K-means, linear, or logistic regressions to improve the performance of your chosen algorithm. Additionally, you have the choice of customizing instances through the Jupyter notebook interface.
Testing and Tuning
Testing and tuning begin with setting up the required libraries, which must be imported. Then list a few environmental factors that must be kept under control so that the model can be trained. After that, tune and train the model. It uses several different algorithm parameters for unbuilt hyperparameter tuning. Data is stored and transferred using the S3 bucket because it is a safe and secure internal AWS resource.
Due to Amazon Elastic Container Registry’s (ECR) high scalability, AWS Sagemaker uses it to deploy Docker containers. While the training algorithm is kept in ECR, the training data is kept in Amazon S3. It also independently creates a cluster for data ingest, training, and storage in AWS S3 buckets. Use Sagemaker Batch Transform to make predictions across the entire dataset; Amazon Sagemaker Hosting to make predictions across smaller datasets.
Deploy
Your model will be prepared for deployment once you have finished tuning it. The deployment of your model and real-time predictions are handled by SageMaker endpoints. The predictions aid in providing information about whether the ML model you developed and implemented is successful in achieving the business objectives. After completing this, you can assess and rate your ML model for future use and enhancements.
What Are the Steps for Training a Model with AWS SageMaker?
Let's discuss using ML compute instances to train the model.
- An Amazon Simple Storage Service (S3) bucket, ML instance, and an image representing the inference code must first be created as a training job.
- The input data for your model should be available in that specific S3 bucket. After the training jobs are created, the ML compute instances are started.
- The model is currently being trained by SageMaker using code and datasets that have been provided by us. AWS S3 buckets are also used to store the outputs and artifacts generated by the process.
- The helper code starts and completes the remaining tasks when the training code fails.
Security on Amazon SageMaker
Cloud Security
AWS uses a shared responsibility model, which includes security in the cloud, to protect the infrastructure and security of the cloud. This model takes into account the services chosen by a customer, IAM key management, and granting different users different levels of privileges, as well as securing the credentials and other information.
Data Security
SageMaker encrypts the data and model artifacts both in transit and at rest. requests a secure (SSL) connection to the Amazon SageMaker console and API. For encrypted notebooks and scripts, an AWS KMS (Key Management Service) key is used. If the permanent key is not available, these are encrypted using the temporary key. When the encryption has been deciphered, this temporary key is useless.
What is Amazon SageMaker Studio?
A fully functional Integrated Development Environment for machine learning is SageMaker Studio (IDE). It combines every feature that is crucial to SageMaker. From a single window, the user can write code in SageMaker Studio's notebook environment, perform visualization and debugging, track models, and check model performance. We make use of the following SageMaker features.
Amazon SageMaker Debugger
The feature vector and hyperparameter values will be tracked by the SageMaker debugger. Investigate the exploding tensor issues, look into the vanishing gradient issues, and save the tensor values to the s3 bucket. It is advisable to store the debug job logs in CloudWatch. Every time the value of the tensors needs to be verified, SaveConfig from the debugger SDK should be used. After that, each debugging job run will begin with a SessionHook connection.
Amazon SageMaker Model Monitor
To monitor the model's performance, the SageMaker model examines the data drift. The defined constraints file and the feature statistics file are both in JSON format. The constraint.json file contains the statistics, the list of features with their types, and the completeness field, whose value ranges from 0 to 1. The completeness field specifies the required status.json The file contains information on the mean, median, quantile, etc. for each feature. The reports are saved in S3, and more information about them can be found in the file constraint violations.json, there will be an accompanying table that shows the names of the features and the type of violation (i.e., the data type, the min, or max value of a feature, etc.).
Amazon SageMaker Model Experiment
The use of SageMaker is more challenging when tracking multiple experiments (training, hyperparameter tuning jobs, etc.). Log the experiment's results after creating an Estimator object. The ability to import values from the experiment into a pandas data frame makes analysis easier.
Amazon's SageMaker AutoPilot
To use ML with AutoPilot, just click. Indicate the data path and the type of the target attribute (regression, binary classification, or multi-class classification). If the target type is not specified, the built-in algorithms automatically specify it, run the data preprocessing, and apply the model based on it. During the data preprocessing stage, Python code is automatically generated for use in subsequent tasks. It is used in a specific custom pipeline. Briefly describe the AutoMlJob API.
I hope you now understand the purpose of Amazon developing AWS SageMaker Studio For Data Scientists and Machine Learning Developers. And also you can contact Infiniticube if you need scalable Model Deployment via Amazon SageMaker.
Sagemaker has been used by our Team of Experts to deploy a wide range of complex machine learning models across multiple industries. In addition, we try to cut as much expense as possible without compromising the quality of the model. We strive to develop AI/ML infrastructure at the lowest possible cost. Our team has developed and deployed models like IoT Data Analysis Models, Computer Vision Models, and Health Record Analysis Models.
If your machine learning team wants to reduce costs and implement highly scalable server-less models, get in touch with us right away. Here, you can leave your specifications or arrange a call with one of our AI experts.







 June 27, 2025
June 27, 2025
 Balbir Kumar Singh
Balbir Kumar Singh
 0
0

Leave a Reply